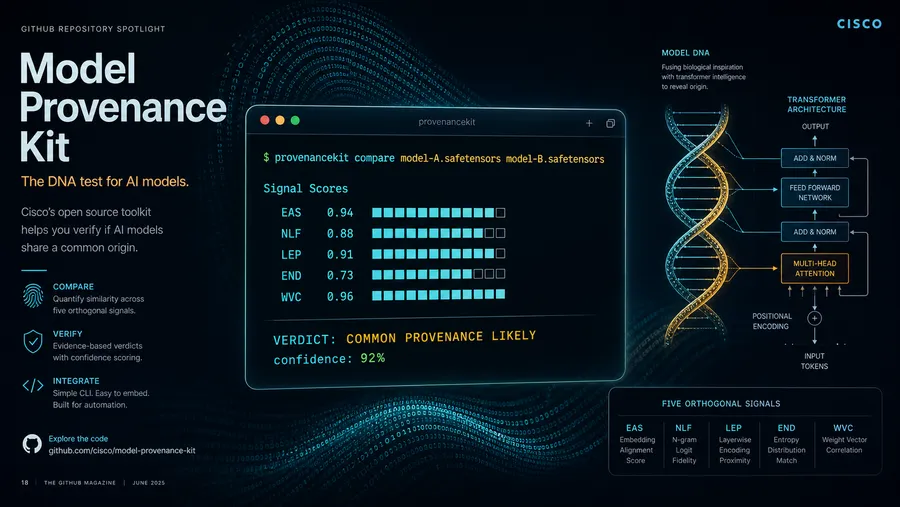
Cisco Model Provenance Kit: A DNA Test for Transformer Weights
Cisco open-sourced a Python toolkit that fingerprints model weights to determine lineage. Installation, CLI walkthrough, and real comparison between models.
Read deep dive →Open-TechStack
No-hype tutorials, model comparisons, agent system design, and technical workflows. Grounded with benchmark measurements.
Our Mission
We run local benchmarks, inspect source repositories, build micro-agents, and audit security layers to keep your tech stack optimized and cost-efficient.
Read About Us →AI Models
Analysis of model architectures, local weights, and fine-tuning parameters.
Explore →AI News
Deep dives into platform changes and standards shaping the market.
Explore →Setup Guides
Configuring local environments and model pipelines.
Explore →Comparisons
Head-to-head performance, cost, and developer benchmarks.
Explore →Security
Defense tactics, audit guides, and secure system boundaries.
Explore →Grounded technical deep dives from our latest issues.
Cisco open-sourced a Python toolkit that fingerprints model weights to determine lineage. Installation, CLI walkthrough, and real comparison between models.
Read deep dive →Toggle filters below to explore active articles and code guides.

Cisco open-sourced a Python toolkit that fingerprints model weights to determine lineage. Installation, CLI walkthrough, and real comparison between models.

Head-to-head comparison of GLM-5.2 and Kimi K2.7-Code on SWE-bench, pricing, context window, and real-world testing — which open-weight coding model fits your workflow?
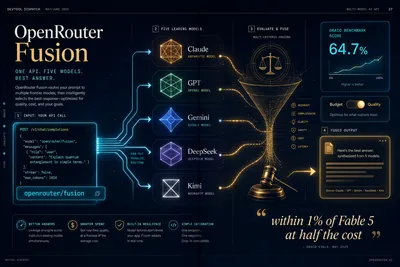
OpenRouter Fusion synthesizes multiple AI models into one answer. A budget panel scored within 1% of Fable 5 at half the cost — benchmarks, API, and decision guide.

The Fable 5 ban and LiteLLM backdoor proved AI supply chain risk is real. How to verify model provenance, audit dependencies, and monitor providers.

Practical guide to OpenRouter and LiteLLM fallback routing — survive Fable 5-style shutdowns, rate limits, and provider outages without changing code.

Technical guide to GLM-5.2 — Z.ai's open-weight 744B MoE model with 1M token context, IndexShare sparse attention, and local execution via llama.cpp.

Hands-on analysis of Moonshot AI's K2.7-Code — 384-expert MoE, $0.95/M tokens, beats Opus 4.8 on MCP tool calling, with API walkthrough and deployment guide.

Our launch editorial explaining what Open-TechStack is all about: practical, benchmarked guidance on AI models, open-source code, and workflows.

The full story of Anthropic's Fable 5 and Mythos 5 suspension — from the Pack Hunt jailbreak to the Washington negotiations and what it means for enterprise AI security.