A model on Hugging Face claims to be trained from scratch. The model card says it is a novel architecture. The metadata looks clean.
How do you know it is not a modified copy of a restricted-weight model with a new config file?
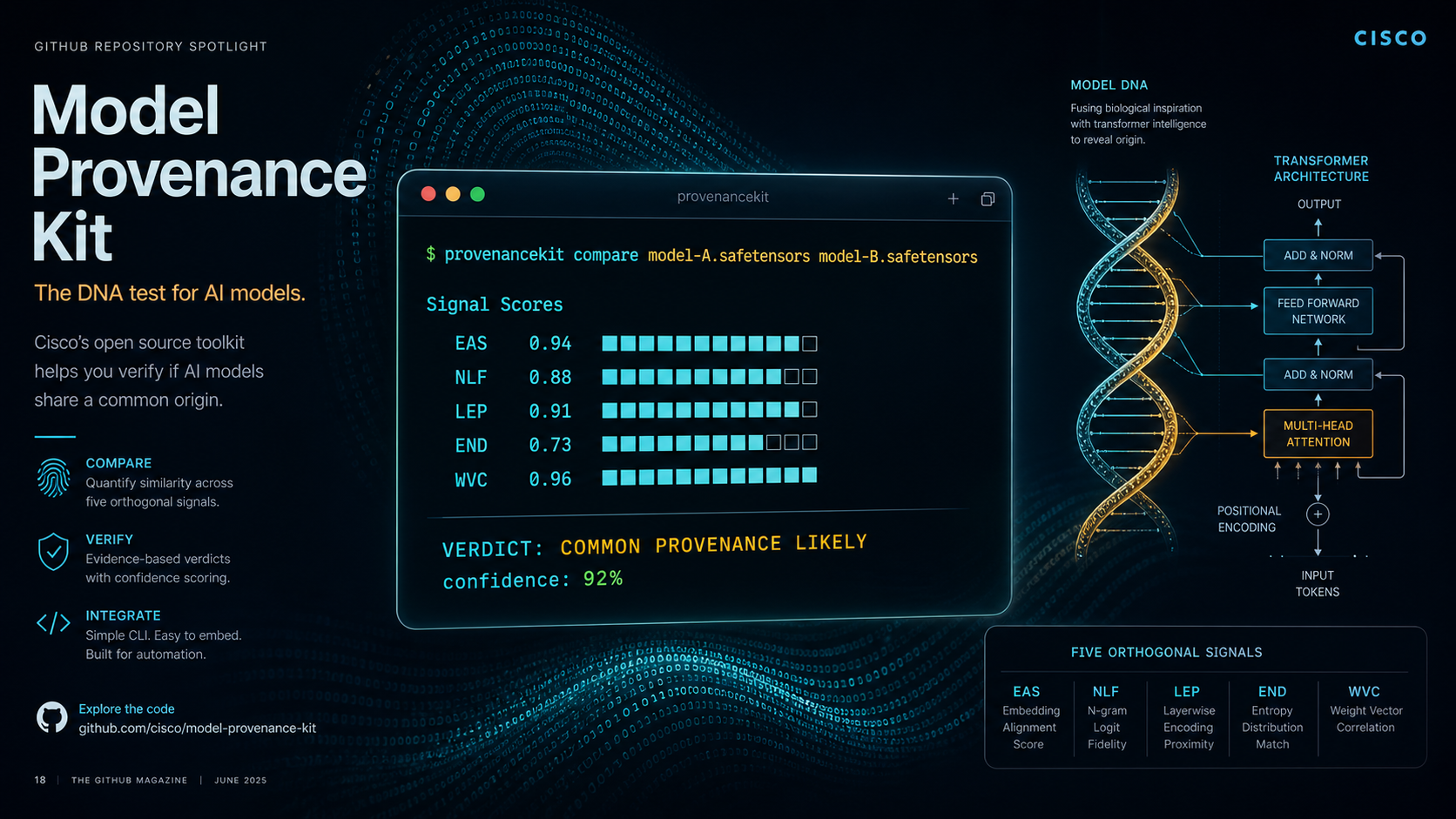
Before April 2026, the answer was basically “trust the model card.” Cisco’s Model Provenance Kit changes that. It is an open-source Python toolkit that examines both metadata and actual learned parameters to determine whether a transformer model derives from a known base model family. Think of it as a paternity test for AI weights.
Repository: github.com/cisco-ai-defense/model-provenance-kit License: Apache 2.0 Language: Python 3.12+ Stars: 92 (fresh, April 2026) Part of: Cisco AI Defense — open-source AI security tools
Why this exists
Over 2 million models on Hugging Face, and almost none have verified provenance. A model card claiming a model was trained from scratch may describe a modified copy of another model. Metadata can be falsified. Config files reveal architecture but not origin — models from Meta, Alibaba, DeepSeek, and Mistral all share building blocks like grouped-query attention and rotary embeddings.
Without provenance information, you cannot know whether a model you are deploying:
- Was derived from a model under export restrictions
- Carries a restrictive license that conflicts with your use case
- Inherits vulnerabilities from a poisoned parent model
- Was fine-tuned from a base you do not have rights to
The Model Provenance Kit addresses this by extracting multi-signal fingerprints from the weights themselves — signals that survive fine-tuning, quantization, LoRA merging, and even vocabulary changes.
Installation
git clone https://github.com/cisco-ai-defense/model-provenance-kit.git
cd model-provenance-kit
uv syncThis installs the provenancekit CLI. Python 3.12+ required.
One-time setup: download weight fingerprints
The deep-signal fingerprints are pre-computed weight features stored as parquet files on Hugging Face. Without them, scans use metadata and tokenizer signals only.
provenancekit download-deepsignals-fingerprint --updateWalkthrough: compare two models
The compare command runs a pairwise analysis between two Hugging Face models:
provenancekit compare z-ai/GLM-5.2 moonshotai/kimi-k2.7-codeThe output includes:
Stage 1 — Metadata screening:
MFI Tier: 3 (weak metadata match — different architectures)
Architecture: GLM-5.2 uses DeepSeek-V4-style MoE, K2.7 uses Kimi MoEStage 2 — Weight signal extraction:
EAS (Embedding Anchor Similarity): 0.12 — unrelated
NLF (Norm Layer Fingerprint): 0.08 — unrelated
LEP (Layer Energy Profile): 0.21 — unrelated
END (Embedding Norm Distribution): 0.15 — unrelated
WVC (Weight-Value Cosine): 0.03 — unrelatedPipeline verdict:
Pipeline Score: 0.12
Verdict: NOT MATCHEDAs expected — two independently trained models from different labs produce near-zero weight correlation. The value here is confirmation: if someone claimed GLM-5.2 was a fine-tune of Kimi K2.7, the signals would prove otherwise.
Walkthrough: scan against the reference database
The scan command matches a single model against the kit’s bundled database of ~150 known base models across 45 families.
provenancekit scan meta-llama/Llama-3.3-70B --jsonThe database covers models from Meta, Google, DeepSeek, Zhipu AI, Moonshot AI, Mistral, Microsoft, NVIDIA, Cohere, OpenAI, and more — ranging from 135M to 70B+ parameters.
scan returns ranked matches with scores and verdict labels, capped by --top-k (default 3) and --threshold (default 0.50).
How the signals work
The pipeline combines three categories of evidence:
| Category | Signals | What it detects |
|---|---|---|
| Metadata | MFI — 3-tier gate from config.json | Architecture family (milliseconds) |
| Tokenizer | TFV (11-component vector), VOA (Jaccard overlap) | Shared tokenizer lineage |
| Weights | EAS, NLF, LEP, END, WVC | Actual learned parameter fingerprint |
The weight signals are what make this work. They are designed to survive transformations that would disguise a model’s origin:
- EAS (Embedding Anchor Similarity): Geometric relationships between token embeddings — unique to a training run, preserved through fine-tuning.
- NLF (Norm Layer Fingerprint): Stability patterns in small normalization layers — resistant to quantization and pruning.
- LEP (Layer Energy Profile): Energy distribution curves across network depth — distinctive even after LoRA merging.
- END (Embedding Norm Distribution): Magnitude distributions encoding word frequency patterns from the original corpus.
- WVC (Weight-Value Cosine): Direct parameter correlation — near zero for independently trained models, high for derivatives.
Signal weights are calibrated via Cohen’s d on a 111-pair benchmark. When a signal returns NaN (e.g., different layer structures), it is excluded and remaining weights are rescaled proportionally.
Score interpretation
| Pipeline Score | Verdict | Meaning |
|---|---|---|
| S = 1.0 or MFI Tier ≤ 2 | Confirmed Match | Same base model, verified by architecture + weights |
| S > 0.75 | High-Confidence Match | Very likely derived from the matched base |
| 0.65 < S ≤ 0.75 | Weak Match | Possible relationship, needs manual review |
| S ≤ 0.65 | Not Matched | No evidence of shared provenance |
The toolkit’s benchmark on a 111-pair test set:
| Metric | Score |
|---|---|
| Accuracy | 96.4% |
| Precision | 98.1% |
| Recall | 94.6% |
| Standard derivatives (fine-tunes, quantizations, LoRA) | 100% recall |
Where it falls short
The benchmark identified 4 misclassifications out of 111 pairs, all at the edges:
- 12-layer → 4-layer distillation (too much structural change)
- Vocabulary rebuild for domain pretraining (tokenizer signals lost)
- Extreme architectural surgery (e.g., swapping attention mechanisms)
The authors document these as fundamental limits. The tool is not a guarantee — it is evidentiary. A “Not Matched” verdict means no signal of shared provenance was found, not that one definitively does not exist.
When to add this to your pipeline
- Before deployment: Run
provenancekit scanon any model you download from Hugging Face to verify its claimed origin. - After an incident: Compare a compromised model against its supposed base to confirm whether it was tampered with.
- For compliance: Generate provenance reports as evidence for regulatory requirements (EU AI Act, NIST AI RMF).
- In CI: Integrate scanning into your model acquisition pipeline to flag unverified weights before they reach production.
The entire pipeline runs on CPU. Architectural screening takes milliseconds. Feature extraction takes seconds to minutes depending on model size, and results are cached for reuse.
Related reading
- AI Supply Chain Security: Model Provenance, Provider Risk, and the Tools to Verify Both — The broader security context this tool fits into
- Multi-Provider AI Gateways: Fallback Routing and Provider Diversity — What to do after you verify your models
Sources
- Cisco — Model Provenance Kit (GitHub)
- Cisco Blog — Introducing Model Provenance Kit
- Help Net Security — Cisco releases open-source toolkit for verifying AI model lineage
- Cisco AI Defense (GitHub Organization)
About the author
Charles Jasthyn De La Cueva is a full-stack developer and the founder of Open TechStack. He writes about AI engineering, developer tools, and practical model evaluation — grounded in real workflows, not press releases.