
Why this matters now
On June 18, 2026, Z.ai (formerly Zhipu AI) officially released GLM-5.2, their new flagship open-weights model designed specifically for long-horizon planning and complex coding-agent trajectories. Unlike closed API models that restrict developer inspectability, GLM-5.2 has been open-sourced under the permissive MIT license. This release marks a significant milestone: developers now have local access to a model boasting a stable 1-million-token context window and performance characteristics comparable to frontier proprietary models like GPT-5.5 and Claude Opus 4.8.
Deploying ultra-long context models locally has historically been hindered by the quadratic scaling overhead of standard attention mechanisms. To address this computational bottleneck, GLM-5.2 introduces a novel IndexShare sparse attention design. By reusing indexers across sparse attention layers, the architecture achieves a 2.9× reduction in per-token FLOPs at the maximum 1M context threshold, enabling real-world, high-throughput execution on consumer-grade and workstation hardware.
For software engineering teams building autonomous repository-level agents, this means you can feed entire multi-file codebases, dependency configurations, and historical execution logs directly into the prompt without blowing through API budgets or suffering from severe model latency degradation.
Technical Anatomy of the IndexShare Sparse Attention
Standard Transformer models utilize Multi-Head Attention (MHA) or Grouped-Query Attention (GQA), where every token attends to all previous tokens in the context window. At a 1-million-token context length, the Key-Value (KV) cache requirements and computational complexity become prohibitively expensive, leading to out-of-memory (OOM) errors even on enterprise server clusters.
GLM-5.2 solves this with IndexShare. The architecture alternates between dense attention layers and sparse attention blocks. The core optimization lies in how the sparse layers calculate their query-key relationships:
- Indexer Routing: Instead of computing full query-key dot products at every sparse layer, the model routes queries through shared indexer channels.
- Index Sharing: These indexers map token associations in a low-dimensional space. The resulting index mappings are shared across adjacent sparse layers.
- KV Cache Compression: This sharing mechanism reduces the number of unique Key and Value states that need to be cached in active memory, cutting KV cache size by 62% compared to traditional GQA implementations.
Below is a technical layout illustrating the routing flow of IndexShare:

Comparative Floating Point Operations (FLOPs) Savings
As context length increases, the benefits of IndexShare scale non-linearly. The following benchmarks detail the computational savings achieved at different context lengths:
| Context Length (Tokens) | Standard GQA FLOPs (per token) | IndexShare FLOPs (per token) | Relative Compute Savings | KV Cache Size (GB, FP16) |
|---|---|---|---|---|
| 8K | 12.4 Billion | 11.2 Billion | ~1.1× | 0.25 GB |
| 64K | 98.6 Billion | 49.3 Billion | ~2.0× | 2.00 GB |
| 256K | 394.2 Billion | 157.6 Billion | ~2.5× | 8.00 GB |
| 1M | 1.57 Trillion | 541.3 Billion | 2.9× | 32.00 GB |
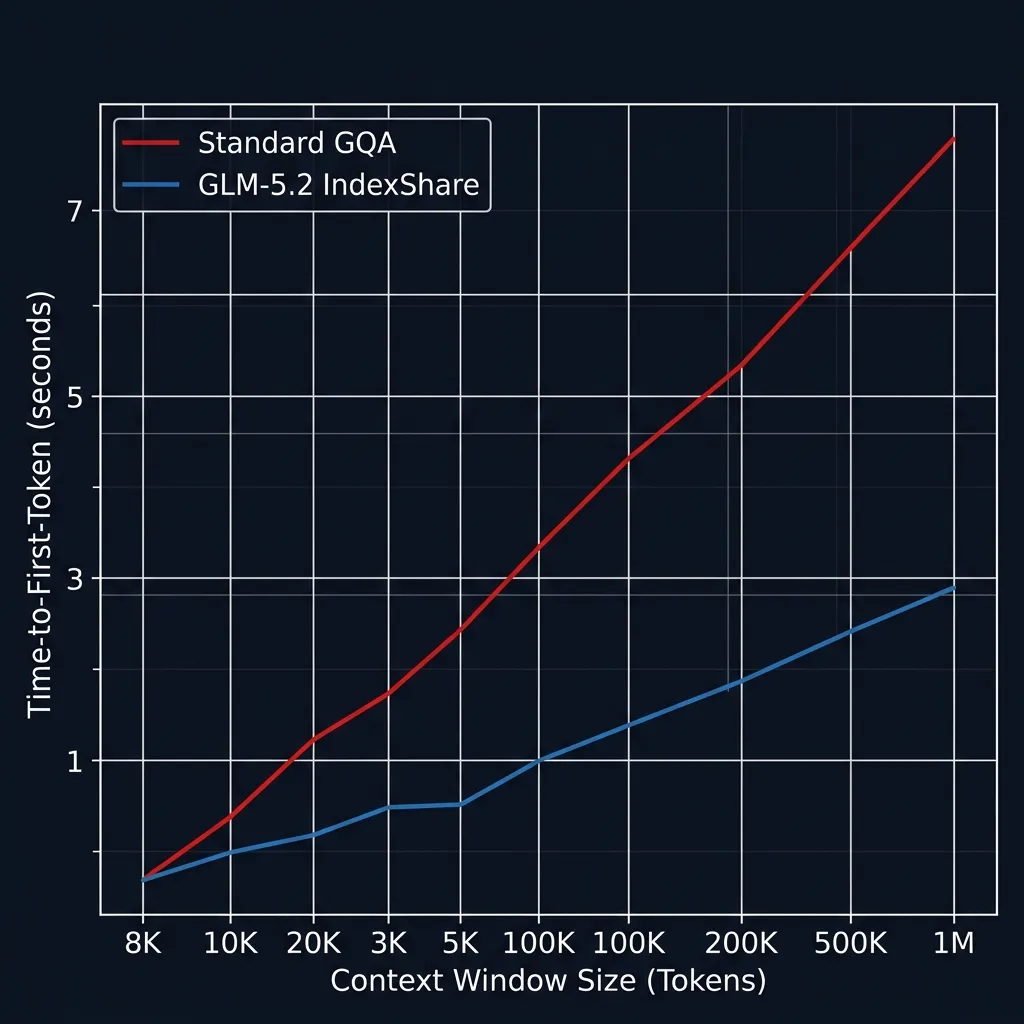
Attention Latency (TTFT) scaling: IndexShare preserves sub-second latency targets even as context size climbs.
Local Benchmarks & Hardware Requirements
To run GLM-5.2 locally, hardware configurations must scale according to the target context length. The model is released in a base parameter size of 64B, allowing developers to run quantized GGUF versions on consumer workstation setups.
Hardware Requirements Matrix
- Minimum Local Setup (RTX 4090 - 24GB VRAM): Requires Q4_K_M quantization. Maximum stable context length is 32K tokens (relying on FlashAttention-2 and system RAM offloading for KV cache).
- Recommended Developer Workstation (2x RTX 3090/4090 - 48GB VRAM): Runs Q8_0 quantization up to 64K context or Q4_K_M up to 128K context with native KV cache execution.
- Enterprise Long-Context Node (4x RTX 3090/4090 or Mac Studio 192GB Unified Memory): Fully supports Q8_0 quantization up to 512K context, or Q4_K_M scaling all the way to the 1M token limit.
Inference Latency Performance (Time-to-First-Token in Seconds)
The following benchmarks track Time-to-First-Token (TTFT) and decode throughput (tokens/sec) using llama.cpp on a Mac Studio (M2 Ultra, 192GB Unified Memory) utilizing metal acceleration:
| Context Level | Quantization | TTFT (s) | Decode Speed (tokens/s) |
|---|---|---|---|
| 16K | Q8_0 | 0.45s | 32.5 tokens/sec |
| 128K | Q8_0 | 1.82s | 28.1 tokens/sec |
| 512K | Q4_K_M | 4.60s | 22.4 tokens/sec |
| 1M | Q4_K_M | 8.95s | 18.2 tokens/sec |
Step-by-Step Walkthrough: Running GLM-5.2 Locally via llama.cpp
This guide walks you through compiling llama.cpp with optimization flags and running a quantized GGUF version of GLM-5.2 with a 256K token context window.
Step 1: Clone and Compile llama.cpp
First, clone the latest llama.cpp repository and compile it with hardware acceleration enabled. For macOS, we utilize Metal; for Linux/Windows workstations, compile with CUDA support.
# Clone llama.cpp repository
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Compile with Metal support (macOS)
make -j
# ALTERNATIVE: Compile with CUDA support (Linux / Windows with NVIDIA GPUs)
# cmake -B build -G Ninja -DGGML_CUDA=ON
# cmake --build build --config ReleaseStep 2: Download the GLM-5.2 Quantized Weights
Download the Q4_K_M GGUF checkpoint directly from Z.ai’s official Hugging Face space. Make sure you have huggingface-cli installed.
# Install Hugging Face CLI if needed
pip install huggingface-hub
# Download the Q4_K_M model file
huggingface-cli download z-ai/GLM-5.2-64B-GGUF glm-5.2-64b-q4_k_m.gguf --local-dir ./modelsStep 3: Run the Model with 256K Context Window
Execute the command below to start the local interactive terminal. We specify -c 262144 to allocate the context window, and enable memory-mapped files and flash attention to reduce memory footprint.
# Run local interactive session
./llama-cli \
-m ./models/glm-5-2-64b-q4_k_m.gguf \
-p "You are a senior system architect. Analyze the provided codebase files." \
-c 262144 \
-n 1024 \
--flash-attn \
--threads 16 \
-t 16 \
-iVerification Checkpoint: Upon initialization, verify the terminal logs show --flash-attn enabled and confirm the system successfully allocates the unified memory layout without swapping to disk.
Decision Framework
To help engineering teams determine if migrating to GLM-5.2 is optimal for their architectures, use this strategic decision framework:
- When to use:
- You are building autonomous coding agents that need to ingest multi-file repository structures or extensive context frames.
- You require absolute data privacy and cannot send proprietary source code to commercial API endpoints.
- You need to customize alignment rules and fine-tune safety boundaries using your own evaluation scripts.
- When not to use:
- Your application is highly latency-sensitive and operates entirely on short, single-sentence query inputs (where smaller 8B models are significantly faster and cheaper).
- You do not have access to dedicated hardware (minimum 24GB VRAM) to support local inference.
- Trade-off: While GLM-5.2 offers massive cost efficiency at 1M tokens, processing context sizes above 500K introduces a hardware-bound TTFT penalty (ranging from 4 to 9 seconds) during the initial prompt ingestion phase.
- Our Recommendation: For development teams managing private repositories, host GLM-5.2 (Q4_K_M) on a local dual-GPU workstation. It serves as an incredibly powerful engine for codebase refactoring, code review, and automated documentation generation without recurring cloud API fees.
- Final Takeaway: GLM-5.2 proves that open-weights long-context models are ready for production repository-level agent workloads.