
Why this matters now
The velocity of the artificial intelligence ecosystem in 2026 is overwhelming. Every single week, developer circles are flooded with hundreds of new model checkpoints, wrapper tools, agent frameworks, and infrastructure protocols. Marketing materials make bold claims: models are declared “revolutionary,” workflows are promised to “fully automate engineering roles,” and cloud solutions promise “zero setup overhead.”
For developers, founders, and systems architects who are actually building, this creates a massive noise problem. Sorting through promotional announcements to find out which tool actually works locally, how much it costs to run at scale, and what safety vulnerabilities it introduces requires hours of testing.
Open-TechStack was built to solve this problem. We are a technical publication and sandbox dedicated to cutting through marketing hype and providing developers with grounded, benchmarked, and reproducible reviews and guides. We don’t write generic summaries; we install the binaries, check out the source code, profile the token usage, measure the latency, and write about what we find.
Current Open-TechStack homepage: the relaunch positions the site as a builder-focused AI journal, not a generic news feed.
What We Cover: Our Six Core Pillars
To give builders a reliable roadmap, we focus our analysis on six key areas where technical clarity yields the highest leverage.
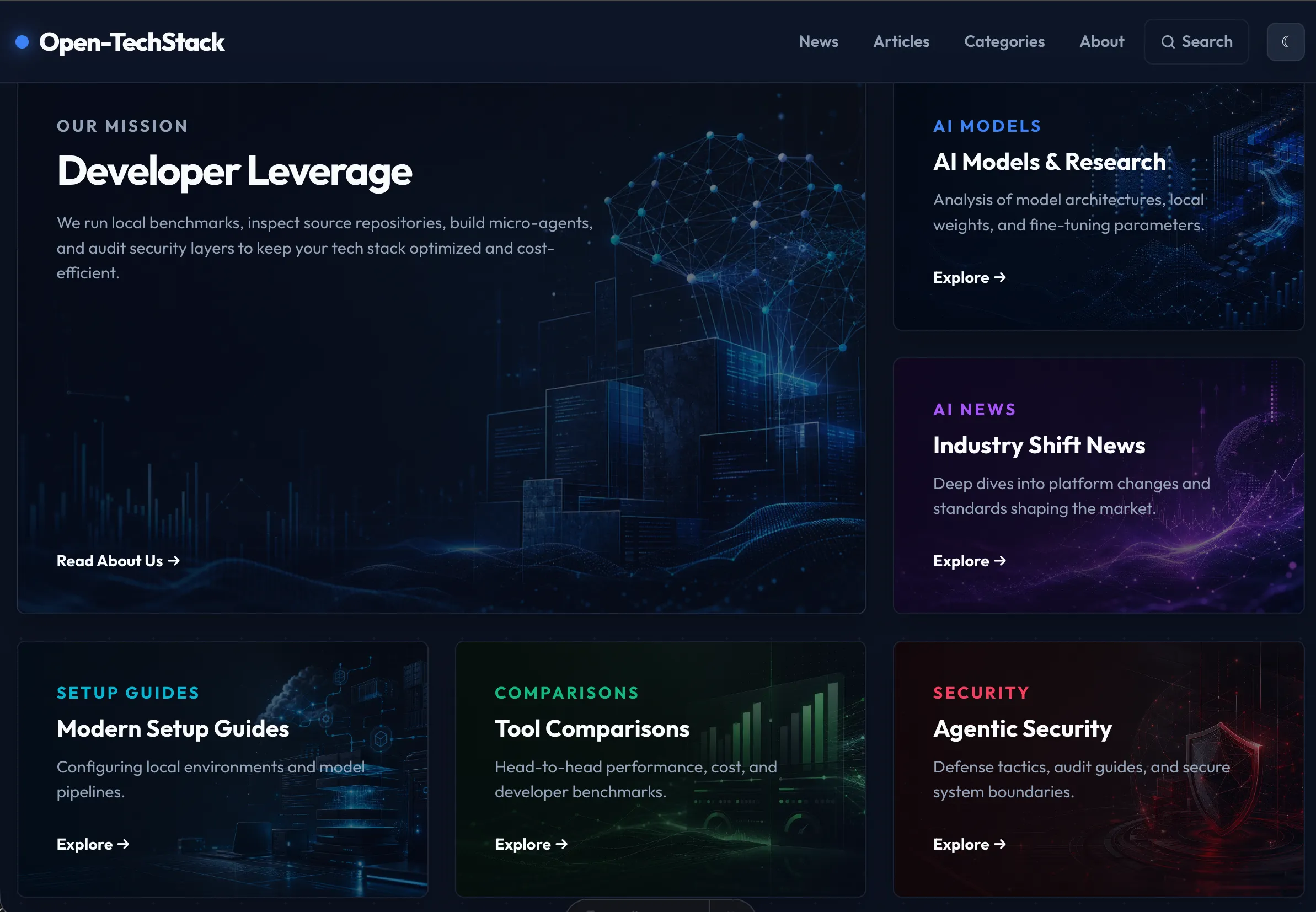
The pillar grid makes the coverage model concrete: mission, models, news, setup guides, comparisons, and security are all presented as clearly defined editorial lanes.
1. AI Models & Research
We demystify the architectures driving modern applications. Whether we are discussing a new open-weights release from Meta, deep dive reasoning models, or local model fine-tuning (e.g., using Unsloth or vLLM), we focus on:
- Hardware Constraints: What GPU size, VRAM footprint, and quantization levels are required for inference.
- Latency Benchmarks: Time-to-first-token (TTFT) and throughput measurements under load.
- Parameter Analysis: Why a specific attention mechanism or context window configuration matters for your queries.
2. Open-Source (GitHub Codebases)
Open-source repositories represent the foundation of developer freedom. We actively search for and evaluate promising repositories, frameworks, and CLI utilities. Our reviews check for code quality, dependency footprints, configuration patterns, and community health. We write guides that explain how to clone, configure, and integrate these repos into your local stack.
3. Tool Comparisons
When faced with choices like Ollama vs. LM Studio or PydanticAI vs. LangGraph, developers need more than a list of features. We run head-to-head testing across real-world workloads, tracking:
- Cost Comparisons: API spending and server resource metrics.
- Reliability Profiles: How frameworks handle exceptions, rate limits, and fallback strategies.
- Developer Experience: The learning curve, type safety, and ease of integration into standard pipelines.
4. Step-by-Step Setup Guides
Every technical tutorial we write contains copy-pasteable commands, configuration files, and verification checkpoints. We assume no magic settings; if a guide requires an environment variable or a specific Docker network bridge, it is written explicitly in the walkthrough steps.
5. Agentic Security & Auditing
As AI agents gain execution capabilities (running commands, using browser tools, and accessing files), the attack surface expands dramatically. We cover:
- Prompt Injection Defense: How to secure system prompts and input boundaries.
- Sandboxing: Configuring secure runtimes, Docker containers, and permission models.
- WAF & CDN Rules: Safely managing incoming agent traffic to prevent scrapers from overloading resources.
6. AI Niches & Workflows
We explore custom workflows that compound developer productivity. This includes configuring personal Obsidian research vaults, building custom CLI assistant scripts, and optimizing local RAG (Retrieval-Augmented Generation) pipelines for private code repositories.
Our Technical Sandbox & Testing Process
To provide reliable insights, we run a dedicated testing sandbox for every tool and model we review. Here is how we verify technical workflows:

- Reproducible Sandboxes: Every configuration is deployed in an isolated environment (such as Docker containers or local virtual machines) to verify dependency settings.
- Performance Benchmarking: We record raw measurements (TTFT, VRAM usage, API latency) to verify physical performance characteristics under load.
- Source Verification: We audit repository source files to check default configuration pathways, security permissions, and licensing profiles.
- Clear Attribution: We link directly to official documentation, source repositories, and primary research papers so readers can easily trace our assertions back to the source.
Relaunch & Production Roadmap
Open-TechStack has recently undergone a complete technical reboot to ensure top-tier performance for our readers. Our frontend stack is built with Astro v5, running on the Cloudflare edge network, and indexed using Pagefind for static search. This configuration ensures page loads under 100ms and avoids slow database cold starts.
In the coming weeks, we will be publishing deep dives on:
- Local Fine-Tuning Pipelines: How to fine-tune open weights models using Unsloth on consumer hardware.
- Secure Agent Architectures: Designing approval pipelines for agents that interact with external file systems.
- LiteLLM Config Blueprints: Managing multiple model fallback layers and track API token usage.
The Start Here page makes the reboot practical: it gives new readers a clear path into the site instead of dropping them into an unstructured archive.
Decision Framework
Should you read Open-TechStack? Here is our clear-eyed framework to help you decide:
- When to read: You are actively building software, setting up model pipelines, or looking to deploy agent systems, and you need exact setup commands, cost breakdowns, and benchmark data.
- When not to read: You are looking for high-level market summaries, startup investment news, or non-technical product commentary.
- Trade-off: Our focus on technical depth means we do not write quick, daily digests. We publish longer, comprehensive articles when there is something substantive to document.
- Our Recommendation: Join the journal to receive technical deep dives directly in your inbox, and start exploring our pillars.
- Takeaway: Open-TechStack is the engineering logbook for modern AI architecture and developer leverage.