
The two models that changed open-weight coding
Within 48 hours in June 2026, two Chinese AI labs released open-weight coding models that set a new bar for what non-proprietary AI can do.
GLM-5.2 dropped on June 13 from Z.ai (Zhipu AI). A 744B-parameter MoE with an MIT license and a 1-million-token context window — it scored as the top open-weight model on SWE-bench Pro.
Kimi K2.7-Code landed a day earlier from Moonshot AI. A 1-trillion-parameter MoE with a Modified MIT license, a vision encoder, and a HighSpeed variant hitting 260 tok/s.
Both are free to download. Both can be self-hosted. Both beat models that cost 10× more on key benchmarks — and both arrived the same week the U.S. government banned Fable 5. Open weights cannot be remotely revoked, and a 1-trillion-parameter model that fits on your hard drive does not ask for permission.
This comparison answers one question: which one should you reach for on Monday morning?
At a glance
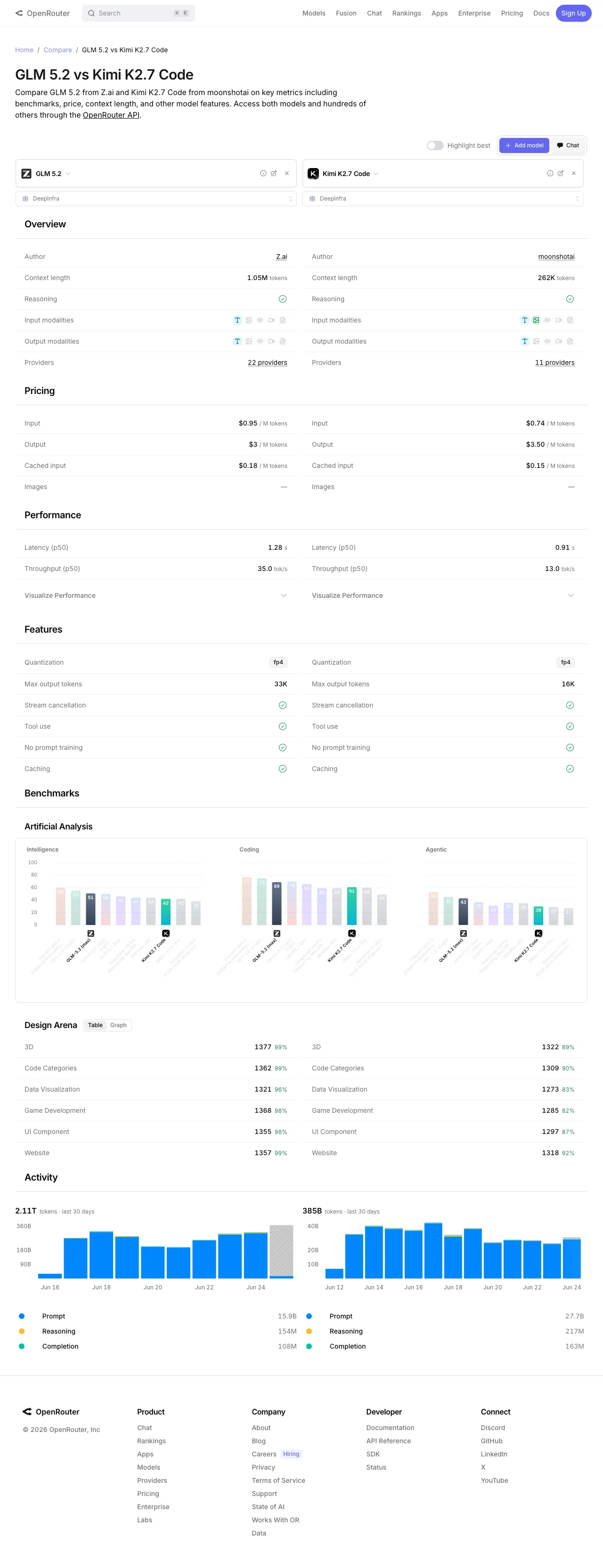
OpenRouter’s comparison page: GLM 5.2 vs Kimi K2.7 Code.
| Dimension | GLM-5.2 | Kimi K2.7-Code |
|---|---|---|
| Developer | Z.ai (Zhipu AI) | Moonshot AI |
| Release | June 13, 2026 | June 12, 2026 |
| Architecture | 744B MoE (~40B active) | ~1T MoE (~32B active, 8 experts) |
| Context window | 1,000,000 tokens | 262,144 tokens |
| Max output | 131,072 tokens | Not published |
| Multimodal | Text only | Vision encoder (images, diagrams) |
| Reasoning mode | Optional | Required |
| License | MIT | Modified MIT (commercial restrictions) |
| Input price | $1.40 / 1M tokens | $0.95 / 1M tokens |
| Output price | $4.40 / 1M tokens | $4.00 / 1M tokens |
| Peak speed | 166 tok/s | 260 tok/s (HighSpeed) |
Benchmarks: where they shine
Fahd Mirza’s real-time head-to-head coding test — both models running inside Hermes Agent.
| Benchmark | GLM-5.2 | Kimi K2.7-Code | Winner |
|---|---|---|---|
| SWE-bench Pro | 62.1% | — | GLM |
| Terminal-Bench 2.1 | 81.0% | — | GLM |
| FrontierSWE | 74.4% | — | GLM |
| MCP Mark Verified | — | 81.1% | Kimi |
| Kimi Code Bench v2 | — | 62.0% | Kimi |
| Composio tool-use (avg) | 0.800 | 0.775 | GLM |
| Terminal-Bench (solves/10) | 5/10 | 5/10 | Tie |
A few caveats on the numbers:
- GLM-5.2’s SWE-bench Pro score makes it the top open-weight model on that benchmark globally. Z.ai published alongside extensive third-party verification.
- Kimi K2.7-Code relies on internal benchmarks (Kimi Code Bench v2, MCP Mark Verified). Independent testers have questioned whether the methodology overstates real-world gains — the 30% thinking-token reduction claim drew particular skepticism from practitioners on Reddit and VentureBeat.
- On practical tool-use testing via Composio (Gmail, Slack, GitHub, Notion, and 18 other integrations), GLM edged ahead by 0.025 points — close enough that individual workflow variance matters more than the average.
Planning vs building: the Kilo test
The most useful comparison came from the Kilo Blog, which tested both models on designing and building a feature-flag service with a deterministic gradual rollout — a real backend task with a deliberate trap.
Phase 1: Planning
Both models designed the service from the same prompt. The plans were scored blindly on a fixed rubric.
| Decision | GLM-5.2 (9.0) | Kimi K2.7 (8.1) |
|---|---|---|
| Flag caching | Cached “no such flag” results and flagged the invalidation trap | Never raised the scenario |
| Environment in hashing | Kept environment out of the hash — explained why users should land in the same slot across envs | Included environment without noting the trade-off |
| API key storage | SHA-256 — reasoned that long random keys don’t need bcrypt’s overhead | Defaulted to bcrypt (standard but costly on every auth request) |
Kimi produced a longer plan with more ready-to-paste code. GLM left fewer decisions unresolved.
“Across both tests, the stronger planner was not the model that wrote the most, but the model that left fewer decisions unresolved.” — Kilo Blog
Phase 2: Building
Both models received the winning plan and built from scratch in fresh sessions:
- GLM passed 15/15 automated integration checks
- Kimi passed 14/15 (missed a cache-clearing edge case)
- Deterministic consistency: Both services returned the exact same on/off result for all 200 test users
Given a solid plan, both models built near-interchangeable implementations. The quality difference was in planning, not execution.
The context window difference
The single clearest difference between the two models.
GLM-5.2 supports 1M tokens natively, enabled by sparse-attention optimizations (IndexShare and KVShare) that reduce FLOPs per token at maximum context. For anything above ~200K tokens — whole-repo analysis, multi-document reviews, long-horizon agent sessions — GLM is the obvious choice.
Kimi K2.7-Code tops out at 262K tokens, and independent reports suggest recall weakens past ~180K. For most coding sessions this is sufficient, but if your workflow regularly involves scanning entire monorepos or processing multi-file issues, GLM’s 1M window is a practical advantage.
Pricing breakdown
Kimi is cheaper on every metric, but the gap narrows in practice:
| Scenario | GLM-5.2 | Kimi K2.7-Code | Savings |
|---|---|---|---|
| 50-file code review (30K in / 5K out) | ~$0.064 | ~$0.0485 | 24% with Kimi |
| 1M-token repo analysis (500K in / 50K out) | ~$0.92 | N/A (exceeds context) | GLM wins by fitting the task |
| Cached requests (hit rate ~40%) | ~$0.26/M in | ~$0.19/M in | ~27% with Kimi |
Quick cost formula to plug your own numbers into:
GLM: (in_tokens × $1.40 + out_tokens × $4.40) ÷ 1,000,000
Kimi: (in_tokens × $0.95 + out_tokens × $4.00) ÷ 1,000,000Kimi’s HighSpeed variant at 260 tok/s also means lower wall-clock cost for interactive coding — you spend less time waiting, even on the same token count.
Which one should you use?
Reach for GLM-5.2 when:
- Your codebase exceeds 200K tokens per session
- You need long outputs (up to 131K tokens)
- You value MIT licensing (no commercial restrictions)
- You are doing repo-scale refactoring, multi-file patches, or terminal-driven engineering
- You plan to self-host
Reach for Kimi K2.7-Code when:
- Your workflow includes images, diagrams, or scanned documents — the vision encoder is an advantage
- You need low-latency interactive coding via the HighSpeed variant
- You want the lowest cost per token for short-session work
- You are building tool-use-heavy agent systems (MCP Mark score suggests strong function-calling)
- Your working context stays under ~180K tokens
Use both when:
The strongest setup today might be Kimi K2.7-Code for interactive agentic coding (vision, tool use, fast iteration) and GLM-5.2 for deep planning, repo-wide review, and long-running tasks. Route through a gateway like LiteLLM and let each model do what it does best.
Related reading
- GLM-5.2: Open-Weight 1M Context Model
- Kimi K2.7-Code: Open-Weight Agentic Coding
- OpenRouter Fusion: Multi-Model API
Sources
- Regolo.ai — GLM 5.2 vs Kimi K2.7 Code: The Definitive Guide
- Kilo Blog — GLM-5.2 vs Kimi K2.7-Code: Planning vs Building
- Artificial Analysis — GLM-5.2 leads open-weight Intelligence Index
- Z.ai — GLM-5.2 Blog on Hugging Face
- MarkTechPost — Kimi K2.7-Code Release
- LLM Stats — GLM-5.2 Model Page
- LLM Stats — Kimi K2.7 Code Model Page
- OpenRouter — GLM 5.2 vs Kimi K2.7 Code Compare
About the author
Charles Jasthyn De La Cueva is a full-stack developer and the founder of Open TechStack. He writes about AI engineering, developer tools, and practical model evaluation — grounded in real workflows, not press releases.