
OpenAI adopting SynthID is a useful signal because it moves AI image provenance closer to an industry stack instead of a single-company label.
Google says OpenAI, Kakao, and ElevenLabs are bringing SynthID technology to more of their AI-generated content. OpenAI’s provenance page also says images generated in ChatGPT and the OpenAI API include C2PA metadata and that the company is adopting SynthID’s imperceptible watermarking for images.
That combination matters.
The next phase of AI media trust will not be solved by one visible label, one metadata field, or one watermark detector. It will need multiple signals that survive different failure modes: invisible watermarking, signed content credentials, verification surfaces in search and browsers, publisher disclosure rules, and user-facing policy enforcement.
This is independent Open-TechStack analysis. It is not official OpenAI, Google, C2PA, legal, or compliance guidance.
TL;DR
OpenAI’s SynthID adoption is not just a branding move. It is a sign that major AI platforms are converging around layered provenance.
- SynthID adds an imperceptible watermark signal to AI-generated media.
- C2PA Content Credentials provide signed metadata about how media was created and modified.
- Google says SynthID has already been integrated across its generative media tools, watermarking over 100 billion images and videos and 60,000 years of audio.
- Google says verification is expanding across Gemini, Search, Chrome, Pixel, and Cloud.
- Google says OpenAI, Kakao, and ElevenLabs are bringing SynthID to more AI-generated content.
- OpenAI says ChatGPT and OpenAI API image outputs include C2PA metadata and that it is adopting SynthID watermarking for images.
- The practical takeaway: treat provenance as a stack, not as a sticker.
The recommendation for builders and publishers: use watermarking and C2PA where available, preserve metadata through your pipeline, show provenance to users, and still keep policy controls for screenshots, re-uploads, edits, and stripped metadata.
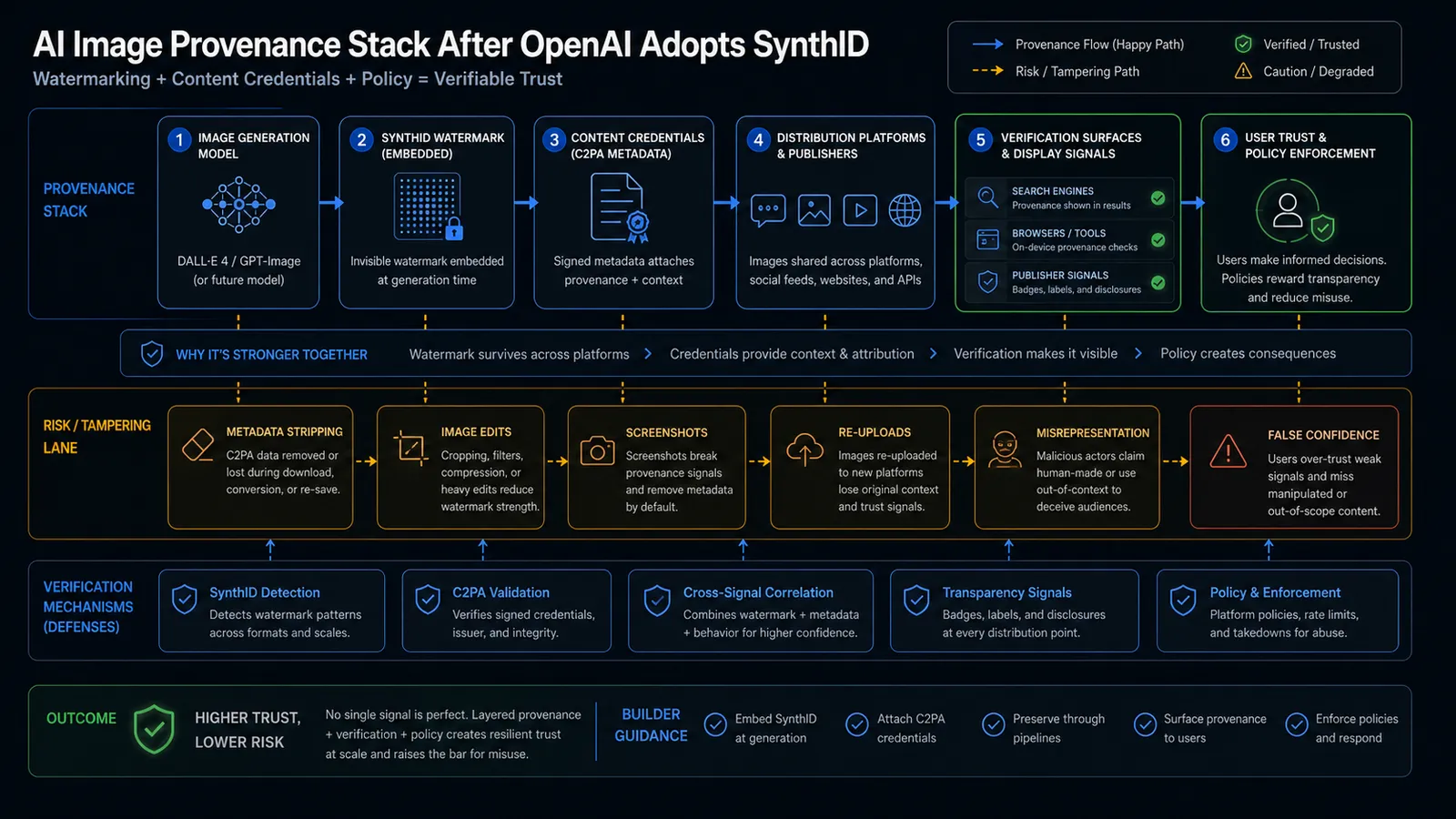
What changed
Google’s announcement says it is expanding content transparency and verification tools in Search, Gemini, Chrome, Pixel, and Cloud. It also says companies including OpenAI, Kakao, and ElevenLabs are bringing SynthID technology to more AI-generated content.
At the same time, OpenAI’s provenance page describes two complementary paths for image provenance:
| Layer | What it contributes | Why it matters |
|---|---|---|
| SynthID | Imperceptible watermarking in generated images | Helps identify AI media even when a normal viewer cannot see a label. |
| C2PA metadata | Signed provenance and creation/editing context | Gives tools and platforms a structured way to display origin and modification history. |
| Verification surfaces | Search, browser, app, publisher, or platform checks | Makes provenance visible at the point where people encounter media. |
| Policy enforcement | Labels, ranking, review, takedown, or fraud workflows | Turns provenance signals into consequences. |
The key shift is interoperability. If AI-generated images travel across websites, social feeds, downloads, screenshots, messaging apps, and publishing systems, provenance cannot live only inside the model provider’s product UI.
Why a watermark alone is not enough
Watermarks are useful because they can be embedded directly into media. But they are not magic.
AI images are edited, compressed, cropped, screenshotted, re-uploaded, recombined, and stripped of metadata. Some transformations may weaken or remove signals. Other workflows may preserve a watermark but lose useful context about who created the image, what tool produced it, or whether it was later edited.
That is why SynthID plus C2PA is more interesting than either layer alone.
Think of it this way:
- The watermark says, “This image likely came from a participating AI generation system.”
- The credential says, “Here is signed context about creation, edits, issuer, and chain of custody.”
- The verification surface says, “Here is what a user, publisher, search engine, or platform can actually see.”
- The policy layer says, “Here is what we do when provenance is present, missing, degraded, or suspicious.”
Without the last two layers, provenance becomes a backend fact that users never see.
Who should care
This is especially relevant for:
- publishers that accept submitted images
- marketplaces with product photos or creator uploads
- social platforms and community sites
- newsrooms and fact-checking teams
- insurers, banks, and trust-and-safety teams reviewing image evidence
- AI app builders generating or transforming user-facing media
- SEO and content teams trying to avoid misleading synthetic assets
If your product handles images that influence belief, identity, money, safety, politics, or reputation, provenance should now be part of your media pipeline.
Implementation checklist
Do not start by asking whether SynthID or C2PA is “perfect.” Start by designing for layered evidence.
Use this checklist:
- Generate: use model providers that emit provenance signals when possible.
- Preserve: avoid stripping C2PA metadata during resizing, conversion, CDN optimization, or CMS upload.
- Detect: add server-side checks for watermarks and content credentials where APIs or tools are available.
- Display: show user-facing provenance when it affects trust, not only in admin logs.
- Degrade gracefully: if metadata is missing, say “unknown” instead of implying “human-made.”
- Log: keep verification results, detector version, timestamp, source URL, and file hash.
- Review: route high-impact images to human review when provenance is missing, inconsistent, or disputed.
- Policy: define what happens for manipulated evidence, misleading uploads, unlabeled synthetic media, and false claims.
That workflow is more durable than a single “AI-generated” badge.
Risk matrix
| Failure mode | What can go wrong | Practical control |
|---|---|---|
| Metadata stripping | C2PA data is removed by download, conversion, CDN, or screenshot workflows | Preserve metadata in the pipeline and log when it disappears. |
| Heavy image edits | Cropping, filters, compression, or recomposition weaken provenance signals | Re-check after every major transformation. |
| Re-uploading | A file loses original context when it moves platforms | Store original source and verification result separately. |
| False confidence | Users treat a weak signal as absolute proof | Use calibrated language: verified, likely, unknown, or altered. |
| Adversarial misuse | Attackers claim “AI” to discredit real media, or claim “real” for synthetic media | Combine technical checks with source, context, and policy review. |
| Inconsistent platform support | One platform shows provenance, another hides it | Make provenance visible in your own product where it matters. |
The most dangerous failure is not “no provenance.” It is provenance that looks definitive when the underlying signal is partial.
What publishers should do next
For Open-TechStack-style publishing, the rule is simple: AI-generated feature images should be internally documented, visually non-misleading, and never presented as real-world evidence unless they are.
For broader publishers:
- keep generation prompts or production notes for editorial images
- label synthetic or illustrative images when they could be mistaken for real events
- avoid using AI images as evidence of a real incident, person, product, place, or claim
- preserve provenance metadata where possible
- add alt text that accurately describes the image as editorial, illustrative, or generated
- do not let ad layout, thumbnails, or captions imply false official endorsement
That is both a trust practice and an AdSense-safe editorial habit.
FAQ
Does SynthID prove an image is AI-generated?
It is a provenance signal, not a universal courtroom proof. It can help identify AI-generated content from participating systems, but publishers should combine it with C2PA metadata, source context, and policy review.
Is C2PA the same as a watermark?
No. C2PA Content Credentials are signed metadata about content origin and changes. SynthID is an imperceptible watermarking technology embedded into generated media. They solve different parts of the provenance problem.
Can screenshots break provenance?
Screenshots can remove metadata and may weaken provenance context. That is why platforms need verification logs, source records, and policy decisions beyond the file itself.
Should AI publishers label every generated image?
If an image could mislead a reader about a real event, person, place, product, or source, label it clearly. Editorial covers and diagrams should also keep provenance records even when the image is obviously illustrative.
Bottom line
OpenAI adopting SynthID matters because it pushes AI image trust toward a layered provenance model.
The right takeaway is not “watermarking solved deepfakes.” The right takeaway is that serious media pipelines now need multiple signals: invisible watermarking, C2PA credentials, verification surfaces, user-facing labels, and policy enforcement.
For builders, the next task is practical: preserve the signals, expose them where trust matters, and design for the cases where provenance is missing, damaged, or intentionally attacked.
Sources
- Google Blog: Identifying AI-generated media online
- OpenAI: Advancing content provenance
- C2PA: C2PA Specifications