
GitHub just changed the default model behind many enterprise Copilot workflows.
On May 17, 2026, GitHub said GPT-5.3-Codex is now the base model for all Copilot Business and Copilot Enterprise organizations, replacing GPT-4.1. In GitHub’s wording, the base model is what an organization uses when it has not approved other models through its own internal review process.
That makes this more than a model-picker update.
For individual developers, the visible change may be simple: a stronger coding model appears in more places. For enterprise admins, platform teams, and engineering leaders, the practical question is different: what changes when the fallback model for a managed coding assistant becomes a long-term-support Codex model instead of GPT-4.1?
This is independent Open-TechStack analysis. It is not official GitHub or OpenAI guidance, legal advice, or a sponsored post.
TL;DR
GPT-5.3-Codex becoming the Copilot Business and Enterprise base model matters because it turns a newer agentic coding model into the default path for organizations that have not explicitly approved another model.
The useful takeaways:
- This applies to Copilot Business and Copilot Enterprise, not Copilot Pro, Pro+, or Free.
- GPT-5.3-Codex replaces GPT-4.1 as the base model for those organizations.
- The model is GitHub’s first long-term-support Copilot model, with availability through February 4, 2027 for Business and Enterprise users.
- It carries a 1x premium request unit multiplier, while GPT-4.1 remains force-enabled at 0x for now and is tied to the June 1, 2026 usage-based billing transition.
- Admins should review model policy, billing expectations, task routing, safety controls, and review discipline, not just announce that a better model is available.
The short version: if your organization treats Copilot as managed developer infrastructure, this is a change-control event.
What GitHub changed
GitHub’s May 17 changelog says GPT-5.3-Codex is now the base model for all Copilot Business and Enterprise organizations. GitHub also says the model replaces GPT-4.1 in that base-model role.
That word base is important.
In a team environment, admins may approve or restrict specific models through internal review. The base model is the model Copilot can use when the organization has not approved other options. That means the default path changes even if a developer never opens the model picker.
The relevant dates are:
| Date | What it means |
|---|---|
| February 5, 2026 | GPT-5.3-Codex launched. |
| March 18, 2026 | GitHub announced LTS and base-model changes. |
| May 17, 2026 | GPT-5.3-Codex became the base model for Copilot Business and Enterprise. |
| June 1, 2026 | GPT-4.1 deprecation is tied to GitHub’s usage-based billing launch. |
| February 4, 2027 | End of the GPT-5.3-Codex LTS availability window for Copilot Business and Enterprise users. |
GitHub’s earlier February rollout made GPT-5.3-Codex generally available across Copilot Enterprise, Business, Pro, and Pro+ through supported Copilot surfaces. The May change is narrower but operationally more important for managed organizations: it changes the default for Business and Enterprise.
Why the LTS label matters
The most enterprise-specific part of this rollout is not only the model name. It is the long-term-support commitment.
GitHub says GPT-5.3-Codex is its first LTS model in partnership with OpenAI and that LTS models are guaranteed to remain available for a full 12 months from launch. For GPT-5.3-Codex, GitHub lists the availability window through February 4, 2027 for Copilot Business and Enterprise users.
That matters because AI coding models create a governance mismatch.
Engineering teams want better models quickly. Security, procurement, legal, and platform teams usually need time to review model behavior, terms, data handling, audit controls, and acceptable-use boundaries. If the default model changes too frequently, internal approval becomes a moving target.
An LTS model gives admins a more stable review object. It does not eliminate review. It makes review less disposable.
The rollout path teams should use
Do not treat the base-model change as a Slack announcement and nothing else.
Use it as a short operational review:
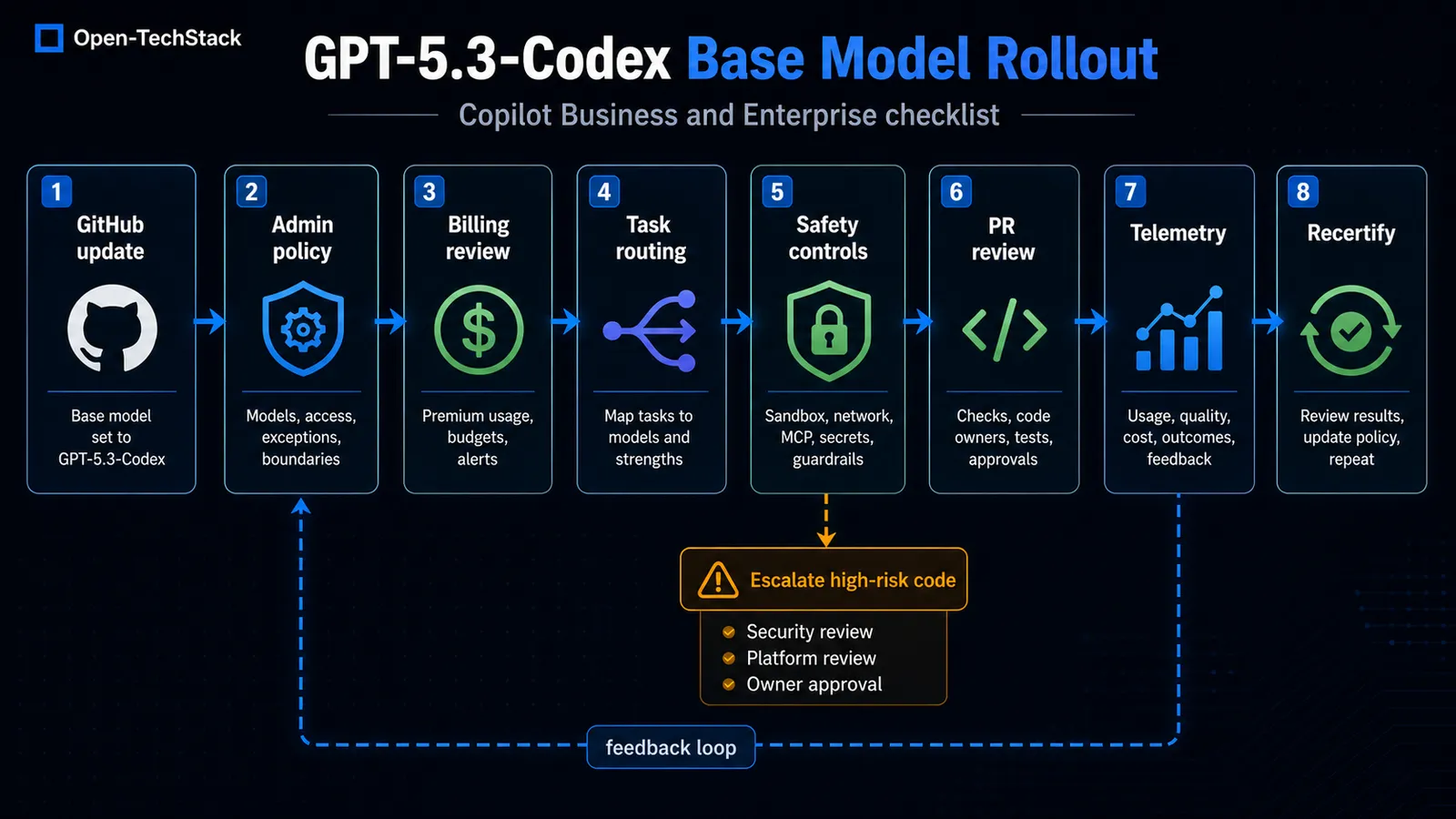
Start with five questions.
| Review area | Question to answer |
|---|---|
| Model policy | Which models are approved, restricted, or allowed by default? |
| Billing | Which teams will generate 1x premium request usage, and who monitors it? |
| Use cases | Which task types should use GPT-5.3-Codex by default? |
| Safety | What controls reduce bad code, data exposure, prompt injection, and unsafe repo actions? |
| Evidence | What metrics show whether the model improves delivery or increases review debt? |
The useful policy is not “everyone can use the newest model.” The useful policy is “this model is approved for these task types under these review rules.”
Model policy checklist
Copilot Business and Enterprise admins should review model settings after the base-model change.
Use this checklist:
- Confirm GPT-5.3-Codex is visible and enabled where expected.
- Confirm whether any teams still depend on GPT-4.1 behavior or pricing.
- Document which Copilot surfaces are in scope: VS Code, Visual Studio, GitHub.com, GitHub Mobile, Copilot CLI, cloud agent, or other supported environments.
- Decide whether developers may manually choose other models or whether auto/default selection is preferred.
- Update internal AI tool documentation so “base model” does not mean “approved for every workflow.”
- Tell developers how to report regressions, unexpected behavior, or cost surprises.
The goal is boring clarity. Developers should know which model path is normal, which path needs approval, and when to switch away.
Billing and quota checklist
GitHub says GPT-5.3-Codex carries a 1x premium request unit multiplier. It also says GPT-4.1 remains force-enabled at 0x for the time being, with deprecation alongside usage-based billing on June 1, 2026.
That makes billing review part of the rollout.
Teams should track:
- current Copilot usage by team or organization
- premium request burn before and after the base-model change
- workflows that generate repeated agentic requests
- whether auto model selection routes tasks differently than expected
- which teams need usage alerts before the June 1 billing transition
This does not mean teams should avoid GPT-5.3-Codex. It means the rollout should not surprise finance, platform operations, or engineering managers after usage-based billing begins.
Where GPT-5.3-Codex should help
OpenAI’s GPT-5.3-Codex system card describes the model as a coding-focused agentic model designed for long-running tasks involving research, tool use, and complex execution. GitHub’s February Copilot rollout said GPT-5.3-Codex improved reasoning and execution for complex, tool-driven, long-running workflows and was faster than GPT-5.2-Codex on agentic coding tasks in early testing.
That points to a practical operating envelope.
Good first default use cases:
| Use case | Why it fits |
|---|---|
| Multi-file maintenance changes | Stronger context handling and tool use can reduce manual stitching. |
| Test generation and test repair | The model can reason from existing code and validation output. |
| Issue-to-PR implementation drafts | The workflow benefits from agentic coding and reviewable artifacts. |
| Refactor planning | The model can map affected files before proposing edits. |
| Code review assistance | It can catch patterns humans may miss, but should not replace reviewers. |
Use more caution with:
| Use case | Why to be careful |
|---|---|
| Authentication and authorization changes | A plausible diff can still create a security bug. |
| Payment, billing, or payroll logic | Small mistakes have direct business impact. |
| Production incident fixes | Time pressure can weaken review discipline. |
| Infrastructure permissions | Tool output may be correct syntactically and still unsafe operationally. |
| Secret handling or data export code | Data exposure risk requires stricter controls. |
The model should raise the ceiling of useful agent work. It should not lower the bar for code review.
Safety controls to keep in place
OpenAI’s GPT-5.3-Codex system card is explicit that coding agents can access powerful tools such as file systems, Git, package managers, and development interfaces. The card also discusses mitigations around sandboxing, network access, and avoiding data-destructive actions.
OpenAI’s Codex product notes similarly emphasize sandboxed environments, network access disabled by default, permission prompts for potentially dangerous actions, and customizable security settings.
Translate that into team policy:
- Keep branch protection and required checks enabled.
- Require human review for agent-produced pull requests.
- Do not let agent output bypass code owners.
- Limit network access for agentic workflows to trusted domains when possible.
- Treat dependency installation and code pulled from the internet as supply-chain events.
- Keep secrets out of prompts, issue comments, and agent-visible logs.
- Require explicit approval before agents run destructive commands, force pushes, migrations, or cleanup scripts.
- Review generated tests carefully so they do not only confirm the generated behavior.
The most dangerous mistake is assuming a stronger model reduces the need for process. For managed coding assistants, stronger models increase the amount of work that can be delegated. That makes review discipline more important, not less.
What to measure after the switch
Teams should measure whether the model improves engineering throughput without increasing cleanup load.
Track:
- time from task assignment to first useful diff
- test pass rate for Copilot-assisted changes
- review comments per AI-assisted pull request
- rate of abandoned agent sessions or discarded suggestions
- number of follow-up prompts needed before the output is useful
- premium request usage by team and workflow
- security or reliability issues found during review
- developer satisfaction by task type, not just general sentiment
The key metric is not “did developers use it?” The better metric is which task classes became cheaper to complete without increasing defect risk?
Starter admin message
Here is a short message teams can adapt:
Copilot Business and Enterprise now use GPT-5.3-Codex as the base model when no other model is approved for a workflow.
Approved initial uses: code explanation, test drafting, small bug-fix drafts, documentation updates, refactor planning, and review assistance.
Higher-risk uses requiring extra review: authentication, authorization, billing, infrastructure permissions, production incident fixes, secrets handling, external data access, and destructive repo operations.
All AI-assisted code changes remain subject to branch protection, required checks, code-owner review, and human approval. Teams should report model regressions, unexpected costs, unsafe suggestions, or repeated review debt to platform engineering.This keeps the rollout practical and avoids turning model selection into an informal developer-by-developer decision.
How this connects to Copilot’s broader direction
This base-model change also fits a larger Copilot pattern.
GitHub has been expanding Copilot across the IDE, GitHub.com, mobile, CLI, cloud agent, and a dedicated Copilot app. We covered the desktop app angle in GitHub Copilot App Technical Preview: Why Agent Sessions Are Moving to the Desktop. The model default matters because all of those surfaces become more operationally important when the underlying coding model is stronger and more stable.
For teams building their own observability around agents, pair this with AI Agent Observability Stack 2026: Traces, Evals, Logs, and Guardrails That Actually Help. Model rollouts are easier to trust when teams can see prompts, tool calls, diffs, tests, and review outcomes in one evidence trail.
The pattern is clear: coding agents are becoming managed engineering infrastructure. Model policy, billing policy, review policy, and telemetry now belong in the same conversation.
SEO FAQ
What changed with GPT-5.3-Codex in GitHub Copilot?
GitHub made GPT-5.3-Codex the base model for Copilot Business and Copilot Enterprise organizations, replacing GPT-4.1 in that role.
Does this apply to Copilot Pro or Free?
No. GitHub says the May 17 base-model change applies to Copilot Business and Copilot Enterprise only. It does not apply to Copilot Pro, Copilot Pro+, or Copilot Free.
How long will GPT-5.3-Codex be available?
GitHub says GPT-5.3-Codex is its first LTS Copilot model and will remain available through February 4, 2027 for Copilot Business and Enterprise users.
Does GPT-5.3-Codex cost more premium requests?
GitHub says GPT-5.3-Codex carries a 1x premium request unit multiplier. Teams should review usage before and after the June 1, 2026 usage-based billing transition.
Should teams let GPT-5.3-Codex write production code?
Teams can use it for production work, but agent-produced code should still go through normal engineering controls: tests, branch protection, code-owner review, security review where needed, and human approval.
Bottom line
GPT-5.3-Codex becoming the Copilot Business and Enterprise base model is a useful upgrade, but the enterprise value is not automatic.
The right response is a lightweight rollout review: confirm model policy, explain billing impact, define safe task categories, preserve review controls, and measure whether the model reduces real engineering work instead of shifting work into cleanup.
If your team already treats Copilot as developer infrastructure, put this on the same checklist as any other platform change. Stronger defaults are helpful only when the operating model around them is clear.
Sources
- GitHub Changelog: GPT-5.3-Codex is now the base model for Copilot Business and Enterprise
- GitHub Changelog: GPT-5.3-Codex long-term support in GitHub Copilot
- GitHub Changelog: GPT-5.3-Codex is now available in github.com, GitHub Mobile, and Visual Studio
- OpenAI: GPT-5.3-Codex System Card
- OpenAI: Introducing upgrades to Codex