
Anthropic’s latest engineering write-up on Claude containment is worth reading because it names the real shift in agent security: the problem is no longer only whether the model makes a mistake. It is how far the mistake can reach.
On May 25, 2026, Anthropic published a detailed look at how it contains Claude across claude.ai, Claude Code, and Claude Cowork. The company frames the issue as blast radius: as agents become more capable, their access grows, and teams need stronger boundaries around what an agent can actually do.
That is the right framing for production teams.
If an agent can browse, read files, edit code, call MCP tools, run commands, or touch internal systems, then prompt safety alone is not enough. The practical question becomes: what hard boundary stops a bad instruction, poisoned document, compromised tool, or model failure from becoming a production incident?
This is independent Open-TechStack analysis. It is not official Anthropic guidance, legal advice, procurement advice, or a sponsored post.
TL;DR
Anthropic’s containment article points to a mature agent security pattern:
- Agent risk has two parts: how likely a failure is and how much damage it can do.
- Human approval prompts help, but Anthropic says approval fatigue is real; its telemetry showed users approved roughly 93% of permission prompts.
- Anthropic emphasizes containment: supervising what the agent is able to do, not only supervising what it decides to do.
- The main containment tools are sandboxes, virtual machines, filesystem boundaries, egress controls, scoped tool permissions, and overlapping defenses.
- Anthropic calls out three defense areas: the model, the environment where the agent runs, and the external content the agent can reach.
- The practical lesson for teams is simple: do not grant agents broad access and hope monitoring catches problems later.
If your team is already adding safety tests, pair this with Microsoft RAMPART and Clarity Show Why Agent Safety Belongs in CI. If you are still designing routing and observability, see the AI Gateway routing playbook and the AI agent observability stack.
What changed
Anthropic’s post is not just a product security update. It is a useful field report from running agents in different containment environments.
The company describes three agentic products with different security needs:
| Product surface | Why containment differs |
|---|---|
| claude.ai | Server-side agent features need hosted isolation around browsing, files, and execution-style capabilities. |
| Claude Code | Local developer workflows must balance productivity with workspace, shell, and user-approval risk. |
| Claude Cowork | Enterprise-style agent work needs stronger isolation, auditability, and operational controls. |
The important lesson is that containment is contextual. A consumer chat feature, local coding agent, and enterprise coworker agent should not share one generic security model.
Why approval prompts are not enough
Approval prompts are useful, but they are a weak single line of defense.
Anthropic says Claude Code previously asked users for permission at each turn, but its telemetry showed users approved roughly 93% of permission prompts. That is exactly the problem many developer tools face: when users see too many approvals, they stop treating each one as a meaningful decision.
Approval fatigue creates a dangerous illusion. The product can claim a human approved the action, while the human may have skimmed a prompt they no longer trust or understand.
That does not mean teams should remove approvals. It means approval must sit inside a stronger system:
- low-risk actions can be auto-approved only inside strict boundaries
- high-risk actions need clearer context and fewer prompts
- dangerous actions should be impossible without scoped permission
- write actions should be logged and reversible where possible
- repeated approvals should not become a substitute for sandboxing
The goal is not more prompts. The goal is fewer, better prompts backed by hard limits.
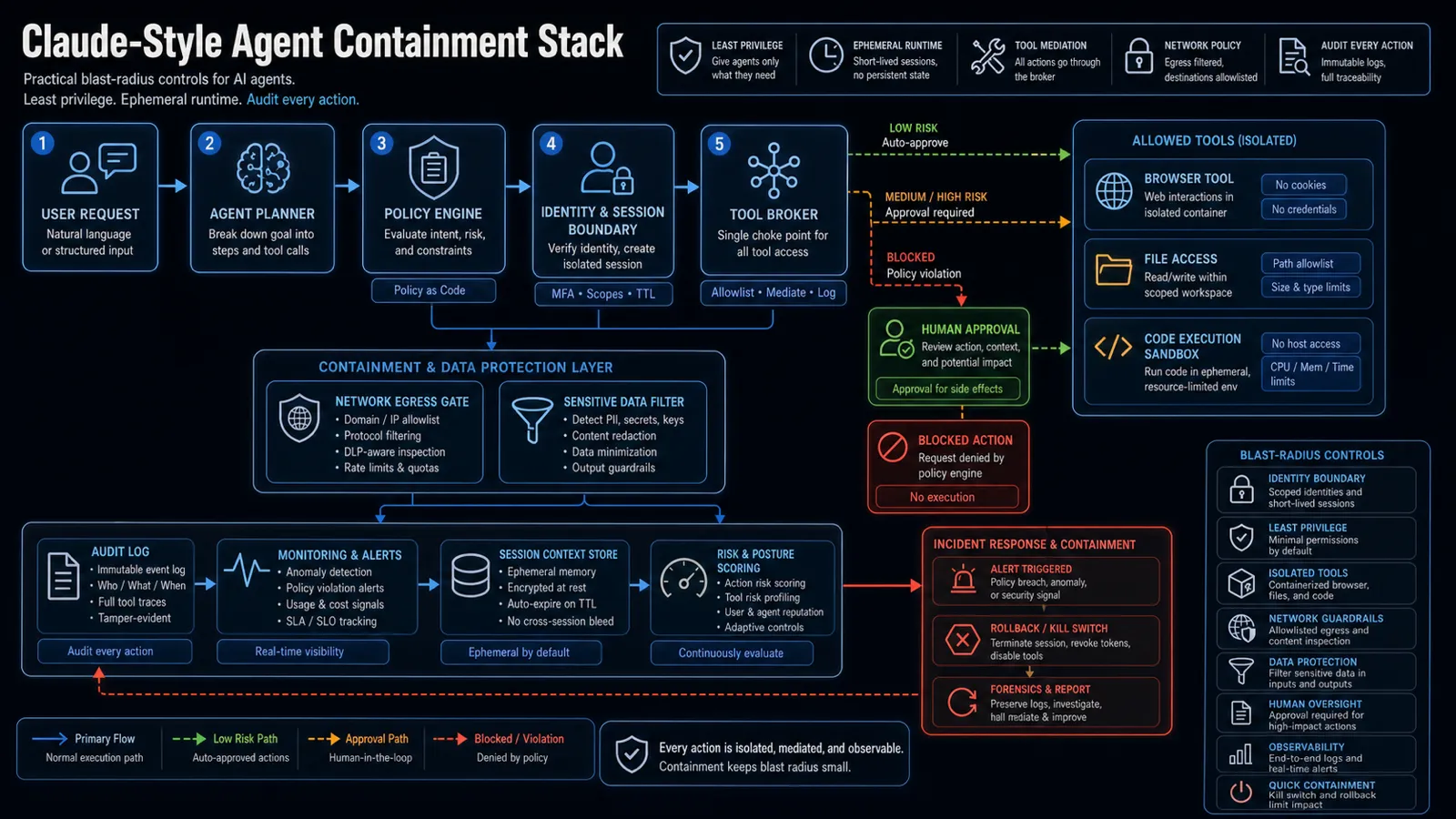
The containment stack
A practical Claude-style containment stack has several layers:
| Layer | What it limits |
|---|---|
| Identity boundary | Which user, workspace, tenant, or service identity the agent can act as. |
| Tool broker | Which tools the agent can call, with what arguments, and under what policy. |
| Filesystem boundary | Which paths can be read or written, and whether host files are exposed. |
| Code execution sandbox | Whether code runs in a short-lived, isolated, resource-limited environment. |
| Network egress gate | Which domains, IPs, protocols, or destinations the agent can reach. |
| Sensitive data filter | Whether secrets, keys, customer data, or unrelated context can leave the boundary. |
| Audit log | Who asked, what the agent did, what tool ran, and what result came back. |
| Kill switch | How a session, token, tool, connector, or runtime can be revoked quickly. |
This is blast-radius engineering. If a poisoned README reaches the model, a malicious webpage gets summarized, or a tool output contains hostile instructions, the containment layer should still limit what can happen next.
Treat external content as hostile
Anthropic makes an important point about external content: an audited connector is not the same thing as audited data.
A connector may be safe as software while still loading untrusted content into the model’s context. A repo, webpage, document, ticket, Slack message, or MCP resource can contain instructions that try to influence the agent.
That means teams should classify content sources by trust level:
| Source type | Safer default |
|---|---|
| Public web pages | read-only, no credential access, no automatic follow-up actions |
| Third-party repos | no secret access, no write access, sandboxed analysis |
| Internal docs | scoped by user entitlement and business need |
| Production systems | read-only by default, write actions approval-gated |
| MCP servers | allowlisted tools, logged calls, bounded outputs |
The dangerous mistake is assuming the model can reliably ignore hostile instructions because the system prompt says so. Prompts help, but boundaries matter more.
Copy this containment checklist
Before giving an agent access to real tools, answer these questions:
- What identity does the agent act under?
- Which tools are allowed, blocked, or approval-gated?
- Which files can the agent read and write?
- Does code execution happen in an ephemeral sandbox?
- Can the agent reach the public internet?
- Are egress destinations allowlisted?
- Are secrets and credentials present inside the sandbox?
- Are tool outputs treated as untrusted content?
- Are high-impact writes logged, reviewed, and reversible?
- Can a session, connector, token, or runtime be killed quickly?
- Which logs prove what the agent did?
- Which tests cover known prompt-injection and tool-misuse paths?
If the answer is “we trust the model,” the design is not ready.
What not to do
Do not give an agent broad credentials and rely on the model to behave.
That is the same mistake as giving every automation script production admin access because the script usually does the right thing. Agents are more flexible than scripts, which makes the boundary problem more important, not less.
Avoid these patterns:
- broad write access when read-only access would work
- host filesystem access when a mounted workspace is enough
- unrestricted internet access for agents that process untrusted content
- MCP tools without allowlists, logging, or output limits
- approval prompts for every small action and no hard block for dangerous ones
- persistent workspaces that keep secrets, state, or poisoned context longer than needed
- observability that records final answers but not tool calls and side effects
Containment is not a sign that the model is bad. It is how serious systems handle powerful automation.
FAQ
What is AI agent containment?
AI agent containment is the practice of limiting what an agent can reach and change through identity boundaries, sandboxes, tool permissions, filesystem limits, egress controls, audit logs, and approval gates.
Why is blast radius important for AI agents?
Blast radius measures how much damage a failure can cause. As agents gain tools, file access, browser access, code execution, and internal context, a single bad instruction can affect more systems unless containment limits the impact.
Are human approval prompts still useful?
Yes, but they should not be the only defense. Approval prompts work best for high-impact actions when the system also uses scoped tools, clear context, logging, and hard boundaries.
How should teams secure MCP tools?
Treat MCP tools as part of the tool boundary. Use allowlists, scoped credentials, explicit permissions, output limits, audit logs, and separate policies for read-only, write, and high-impact actions.
Bottom line
Anthropic’s containment write-up is a reminder that agent security has to become architecture.
The safe path is not to ask users to approve more prompts or to write a longer system instruction. The safe path is to constrain what the agent can reach, isolate where it runs, mediate every tool, filter network egress, audit every action, and keep a fast kill switch.
As agents get more capable, containment is what keeps productivity from turning into uncontrolled blast radius.