
How Teams Use MCP Servers for Real Internal Tooling is a high-impact topic because repository choice determines your long-term velocity, not just your first prototype. In RAG systems, weak repo selection often causes hidden operational costs: brittle ingestion flows, poor observability, weak evaluation, and difficult upgrades. Strong repository choices, on the other hand, compress delivery time and reduce failure rates across the entire lifecycle.
This guide focuses on free and open-source repositories and gives you a practical path from shortlist to production. The goal is not to copy a trend list; it is to choose tools that match your architecture constraints, team skill level, and reliability requirements.
What to evaluate before selecting repos
Use these criteria when shortlisting repositories for RAG pipelines:
- Pipeline coverage: ingestion, chunking, retrieval, generation, and evaluation support.
- Operational readiness: logging, retries, error handling, and maintainability.
- Ecosystem health: release activity, issue responsiveness, and community adoption.
- Interoperability: compatibility with your vector DB, model serving layer, and orchestration stack.
- Governance fit: license clarity, security posture, and reproducible deployment patterns.
If a repo scores high in demos but low in operations, treat it as experimental and isolate it from critical workloads.
Best GitHub repositories to start with
| # | Repository | Why it belongs in a RAG stack |
|---|---|---|
| 1 | langchain-ai/langchain | Framework for building RAG chains with retrievers, tool calling, and memory patterns. |
| 2 | run-llama/llama_index | Data framework for ingestion, indexing, retrieval orchestration, and agentic RAG flows. |
| 3 | deepset-ai/haystack | Production-ready RAG pipelines with retrievers, generators, and evaluation components. |
| 4 | stanfordnlp/dspy | Declarative framework for optimizing prompting/programs in retrieval-augmented systems. |
| 5 | explodinggradients/ragas | Evaluation toolkit for measuring faithfulness, relevance, and RAG answer quality. |
| 6 | BerriAI/litellm | Routing and fallback gateway for multi-model LLM backends in RAG stacks. |
These repositories are complementary rather than mutually exclusive. Many strong stacks combine an orchestration framework, an evaluation toolkit, and a gateway/routing layer for model resilience.
Reference architecture for a repository-first RAG stack
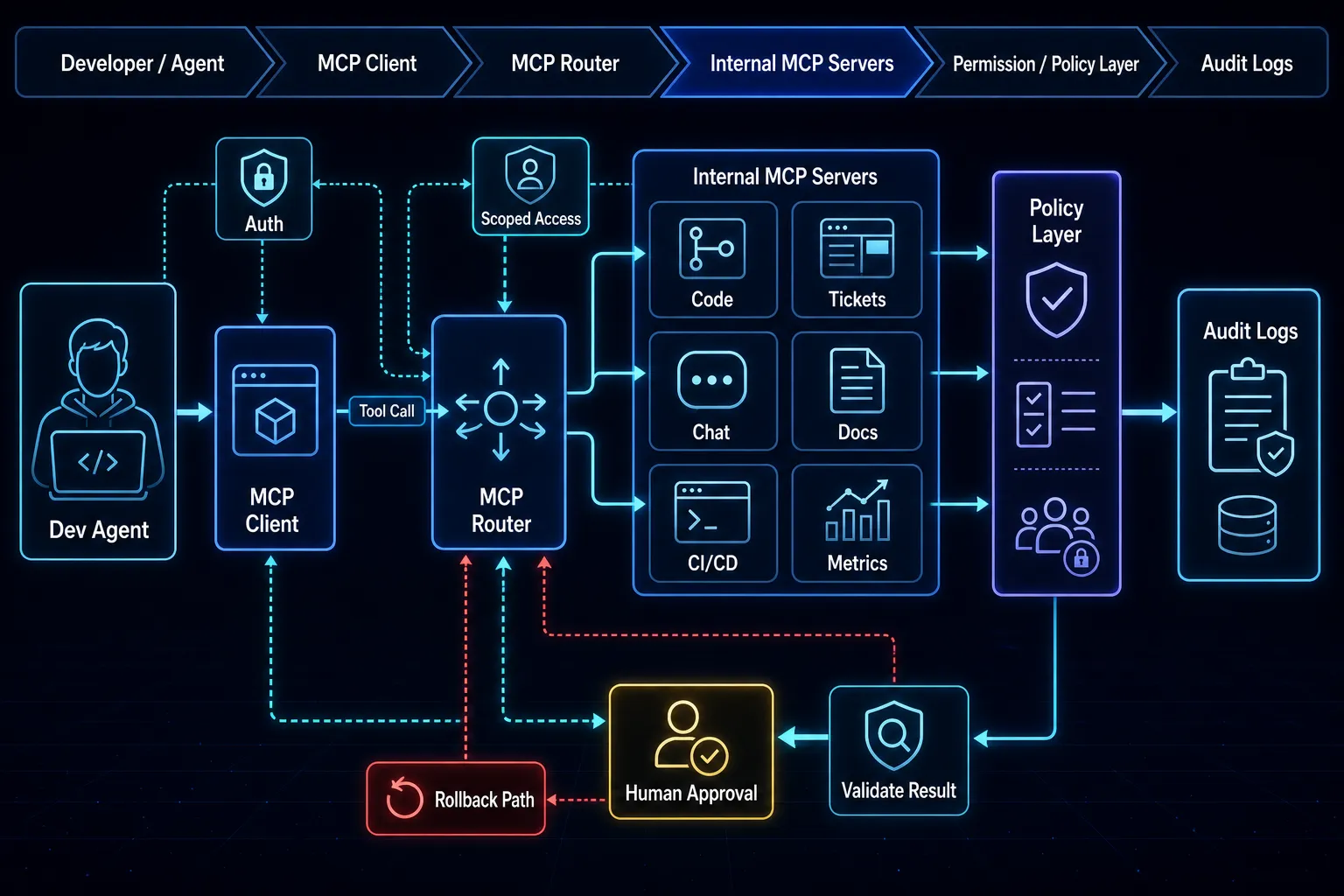
A resilient architecture usually follows this flow:
- Ingestion layer: loaders + normalization + document versioning.
- Indexing layer: chunking strategy + embeddings + vector storage.
- Retrieval layer: hybrid retrieval, reranking, context assembly.
- Generation layer: model routing, fallback policy, output constraints.
- Evaluation layer: faithfulness/relevance metrics and regression checks.
Keep each layer modular. The easiest way to avoid lock-in is to define clear interfaces between retrieval, generation, and evaluation.
Implementation plan (from zero to reliable)
Step 1 — Build a minimal vertical slice
Pick one real workflow (for example, policy Q&A, repository assistant, or support triage). Build a vertical slice that goes end-to-end from ingestion to answer output. Avoid multi-domain scope in the first week.
Step 2 — Add observability early
Add request tracing, prompt/context logs, and retrieval diagnostics before broad rollout. If a team cannot explain why a bad answer happened, improvement loops become guesswork.
Step 3 — Add evaluation gates
Use automated checks for retrieval relevance and answer faithfulness. A lightweight evaluation gate before deployment prevents silent quality drift.
Step 4 — Introduce fallback routing
Add at least one fallback model/provider path so transient outages do not stop your pipeline. Route failures gracefully and monitor fallback frequency as a quality signal.
Step 5 — Harden operations
Define runbooks for reindexing, schema migration, rollback, and incident response. Most production incidents are operational, not theoretical-model failures.
Common mistakes and how to avoid them
- Choosing by stars alone: stars indicate popularity, not operational fitness.
- Skipping evaluation: without metrics, quality regressions are discovered too late.
- Over-indexing context: larger context windows do not fix weak retrieval.
- Ignoring versioning: unversioned embeddings and indexes break reproducibility.
- Treating costs per token as total cost: include engineering and incident overhead.
30-day production readiness checklist
- Define baseline KPIs: task completion rate, first-pass quality, and cost per resolved task.
- Verify at least one fallback route and one rollback strategy.
- Stress-test malformed data, empty retrieval results, and long-context edge cases.
- Confirm logging and access controls for compliance-sensitive data.
- Lock dependency versions and document upgrade strategy.
TL;DR
If your team is adopting MCP for internal tooling, prioritize governance + observability before feature breadth. In practice, teams that define permission scopes, audit trails, and fallback behavior in week 1 reach stable production faster than teams that optimize prompts first.
Practical recommendation
If you are deciding what to implement this quarter, use this decision matrix:
- Use MCP now when you need consistent tool invocation across 3+ internal systems (for example Jira + GitHub + Slack), have at least one engineer who can own policy enforcement, and can measure incidents weekly.
- Do not use MCP yet when your internal APIs are still unstable, role/permission models are undocumented, or there is no owner for audit and rollback.
- Trade-off to accept: MCP reduces integration sprawl, but adds an operations surface area (auth scopes, policy enforcement, tool contracts) that must be maintained like any production platform.
A practical first milestone is a 14-day pilot with explicit targets: reduce manual context-switch time by 20%, keep tool-call failure rate below 2%, and log 100% of privileged tool invocations. If these thresholds are not met, pause expansion and harden contracts before scaling.
For implementation patterns, compare orchestration options in Agent Frameworks in 2026 and production runtime guidance in vLLM Production Guide. For desktop/local workflows that feed MCP-connected tooling, see Ollama vs LM Studio.
Additional implementation notes
For MCP adoption, define trust boundaries per server from day one. Classify servers as read-only, low-risk write, or privileged write, then bind each class to explicit approval policies. This keeps tool invocation predictable and prevents accidental privilege escalation when new connectors are added.
Instrument every MCP action with actor, tool, arguments hash, and outcome status for auditability. Teams that log only final answers lose forensic visibility. A simple weekly audit of rejected vs approved calls often surfaces policy gaps faster than feature QA alone.
Decision expansion
- When to use: use MCP when you need standardized tool contracts across multiple agent runtimes.
- When not to use: avoid broad production access before policy, auth, and audit pipelines are in place.
- Trade-off: tighter approval controls reduce risk, but can add friction until safe defaults and policy templates mature.
Step screenshots
Sources
- learn.microsoft.com — Work IQ MCP overview (preview) | Microsoft Learn
- newsletter.pragmaticengineer.com — Building MCP servers in the real world
- learn.microsoft.com — MCP Server | Microsoft Learn
- reddit.com — r/mcp on Reddit: How are teams deploying MCP servers for enterprise use?
- learn.microsoft.com — MCP | Microsoft Learn
- devblogs.microsoft.com — Announcing the Microsoft Teams SDK (Formerly the Teams AI Library) - Microsoft 365 Developer
Related posts
- Ollama vs LM Studio
- vLLM Production Guide
- OpenAI Agents SDK with MCP approvals
- Promptfoo red-teaming workflow
Screenshots
