TL;DR
This article highlights the practical decision points, constraints, and next actions so you can apply the guidance quickly.
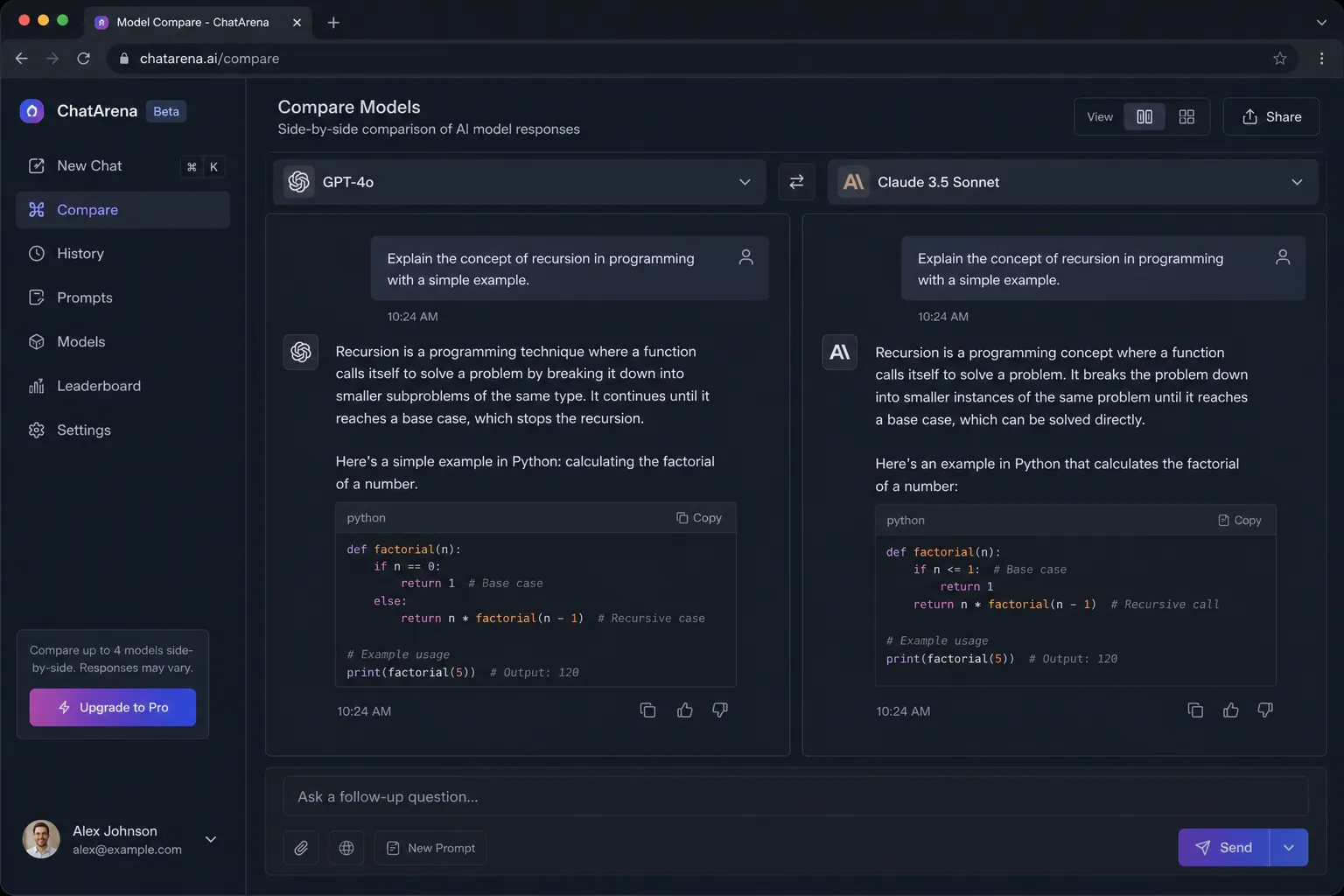
Claude 3.7 vs GPT-4.1: Model Face-off is not a spec-sheet decision. Teams usually evaluate these platforms under pressure: deadlines, limited budget, and mixed workloads that include retrieval, automation, collaboration, and governance. This comparison focuses on how each option performs in real operations rather than marketing checklists.
The most important framing is use-case fit. A tool can look stronger in isolated demos but still fail under production conditions if it introduces brittle dependencies, poor observability, or expensive failure recovery. The opposite can also be true: a seemingly simpler platform may produce better outcomes because it is easier to maintain and scale.
Decision criteria that matter in production
When deciding between Claude 3.7 and GPT-4.1: Model Face-off, prioritize criteria that survive real-world constraints:
- Workflow reliability — how often outputs are usable without manual rework.
- Integration effort — how hard it is to connect the stack to your current systems.
- Operational transparency — logs, tracing, and debugging support.
- Cost predictability — not only token cost, but engineering and maintenance overhead.
- Control and portability — ability to avoid lock-in and preserve deployment flexibility.
Side-by-side comparison
| Dimension | Claude 3.7 | GPT-4.1: Model Face-off |
|---|---|---|
| Onboarding speed | Better when teams need quick adoption and lower setup friction. | Better when teams can invest up-front for longer-term control. |
| Customization depth | Strong for common workflows and faster defaults. | Strong for advanced tuning and non-standard pipelines. |
| Observability | Adequate for small-to-medium deployments with standard metrics. | Better for teams that need deep tracing and diagnostics. |
| Ecosystem maturity | Often easier for mixed-skill teams and faster handoffs. | Often better for engineering-heavy teams optimizing at scale. |
| Best fit | Delivery-focused teams optimizing time-to-value. | Platform-focused teams optimizing control and extensibility. |
Architecture implications

Both options can work in high-quality stacks, but they shape architecture differently. If your workload needs strict governance, explicit fallback routing, and comprehensive audit logs, choose the path that exposes configuration in predictable, inspectable layers. If your workload needs rapid experimentation and faster feature throughput, choose the path that reduces integration friction while preserving core controls.
A useful strategy is phased rollout: start with one bounded workflow, track outcome metrics for two weeks, then expand only if quality and reliability hold under realistic volume. This avoids large rewrites and protects delivery velocity.
Recommendation by team profile
- Small delivery teams: choose the option that minimizes setup and maintenance overhead.
- Platform/SRE-heavy teams: choose the option with stronger instrumentation and control surfaces.
- Compliance-sensitive organizations: prefer explicit policy controls, stable versioning, and reproducible runs.
- Cost-constrained operations: evaluate cost per completed task, not raw request pricing.
30-day validation plan
- Week 1: implement a pilot workflow and establish baseline metrics.
- Week 2: run side-by-side A/B tests on realistic tasks.
- Week 3: stress-test failure paths (timeouts, malformed outputs, quota limits).
- Week 4: decide adopt/defer/narrow-scope based on measured outcomes.
This plan keeps decision quality high and reduces the risk of expensive rework.
Bottom line
The better choice between Claude 3.7 and GPT-4.1: Model Face-off depends less on feature count and more on execution context. Pick the platform that your team can operate reliably, observe clearly, and evolve safely over time. In most environments, operational fit beats theoretical capability.
Practical read
Claude 3.7 tends to make sense when the job is long, nuanced, and sensitive to writing quality. GPT-4.1 is usually the better default when you want a more general-purpose assistant that still performs well across mixed tasks. The decisive factor is whether your team cares more about prose quality and careful reasoning, or about broad versatility and easy integration.
If you are standardizing one model for a team, do not optimize only for benchmark scores. Optimize for the day-to-day friction your people actually feel: handoff quality, edit distance, and how much supervision the model needs before the output is usable.
In practice, the safest rollout pattern is to assign one benchmark task that matters to your team, then compare the edit burden and the number of follow-up questions each model produces. A model that looks slightly weaker on paper can still be the better business choice if it cuts review time and reduces correction loops across the whole workflow.
Sources
- promptfoo.dev — Claude Vs Gpt — Step-by-step tutorials for evaluating LLMs, comparing models, and testing integrations with promptfoo
- docsbot.ai — Gpt 4 1 — The model has a knowledge cutoff of June 2024 and costs $2.00 per million tokens for input and $8.00 per million tokens for output, with a 75% discount for cached inputs. G
- docsbot.ai — Claude 3 7 Sonnet — The model shows particularly strong … Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. Claude 3.7 Sonnet is 2 months older than GPT-4.1…
- reddit.com — We Benchmarked Gpt41 Its Better At Code Reviews — This is an AI generated reddit post linking to an AI generated blog post about 2 AI models competing to generate code, which was then judged by another AI model. All for the purpos
- openrouter.ai — Claude 3.7 Sonnet — Compare GPT-4.1 from OpenAI and Claude 3.7 Sonnet from Anthropic on key metrics including benchmarks, price, context length, and other model features.
Related posts
Screenshots