
FastAPI + vLLM Ecosystem News: Production Updates deserves attention because it touches the practical trade-offs that matter to AI builders: capability, cost, deployability, and control. Instead of treating this as hype, this analysis focuses on whether the update improves day-to-day execution for teams shipping real workflows.
What happened
Based on the available sources, this update represents a meaningful shift in the AI tooling or model landscape rather than a minor feature increment. The change is relevant because it can alter how teams choose providers, how quickly they ship features, and how much operational risk they carry when workloads scale.
For operators and technical leads, the key first step is to separate announcement language from production reality. That means checking what was officially released, what remains in preview, what pricing and limits apply, and what integration work is required before value can be realized.
Why it matters now
Most AI stacks fail not because the model is weak, but because workflow reliability, observability, and governance are weak. A new platform or release only matters if it improves one or more of these dimensions with measurable impact.
For Open-TechStack readers, the highest-signal questions are:
- Does this reduce engineering effort for common tasks?
- Does it improve quality per dollar for real workloads?
- Does it preserve deployment flexibility and portability?
- Does it improve controls for security, compliance, and auditability?
If the answer is “yes” on at least two of those, the release is likely worth piloting.
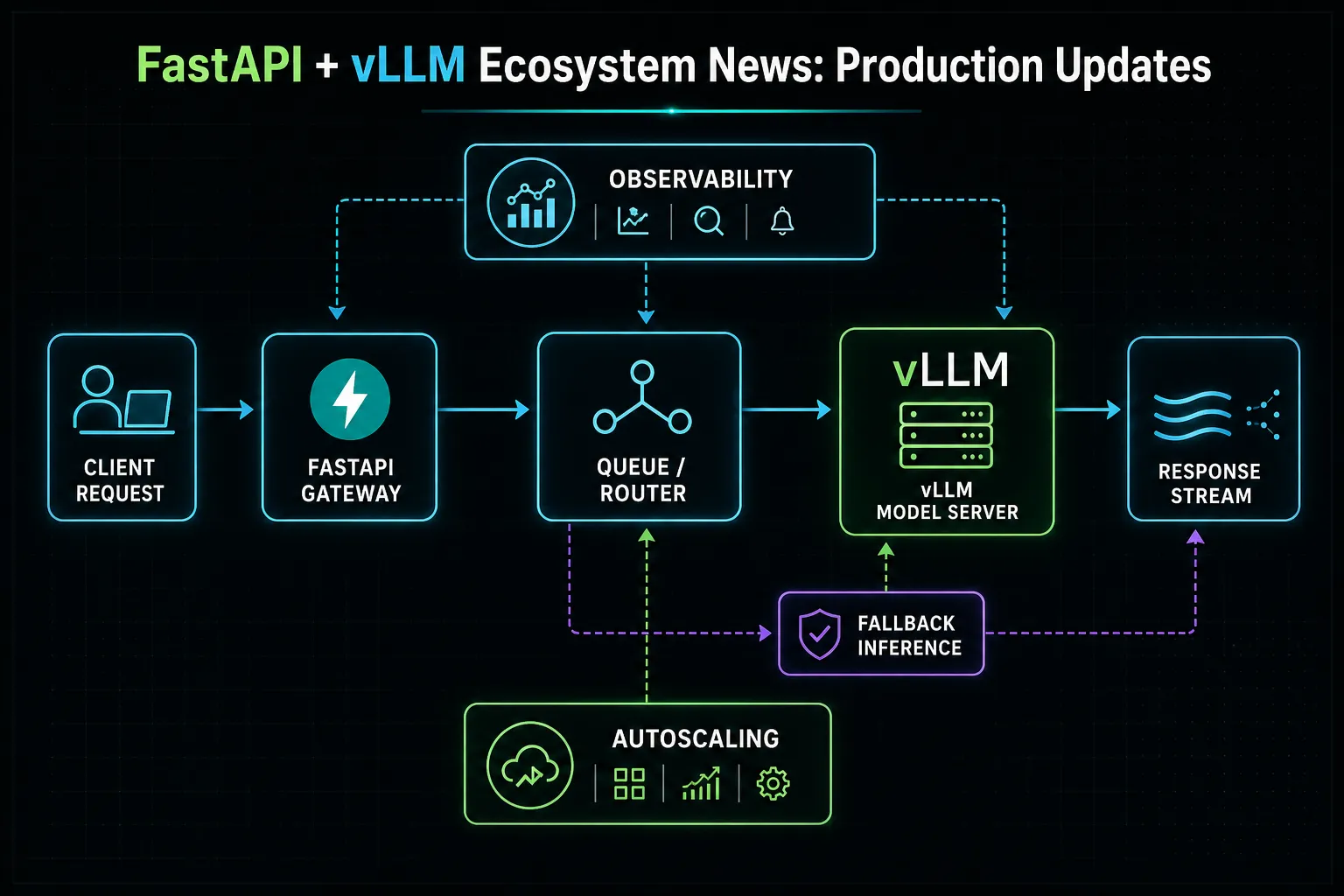
Media note: This is a generated Illustration (concept graphic), not a product screenshot.
Practical impact by team
Product and delivery
Teams can use this update to shorten iteration loops if integration is straightforward and model behavior is stable. The practical win is faster time-to-first-prototype and fewer blocked handoffs between product and engineering.
Engineering and platform
Platform teams should evaluate deployment complexity, fallback behavior, and observability hooks before rollout. A feature that looks strong in demos can still create outages if retries, rate limits, or model drift are not handled intentionally.
Governance and leadership
Leaders should evaluate risk concentration. If this release pushes your stack toward tighter vendor coupling, introduce fallback providers, clear runbooks, and an explicit rollback path from day one.
30-day evaluation plan
- Week 1 — Baseline: capture current latency, quality, and cost-per-task metrics.
- Week 2 — Pilot: run controlled A/B tests on 2–3 realistic workflows.
- Week 3 — Stress test: test failure modes (rate limits, malformed outputs, degraded retrieval).
- Week 4 — Decision: adopt, defer, or narrow-scope rollout based on measured outcomes.
A disciplined evaluation is better than immediate full adoption. The goal is not to be first to try a release; the goal is to improve reliability and output quality without increasing operational fragility.
Decision checklist
- Validate claims against official release docs and independent testing.
- Confirm pricing, quotas, and terms for your expected workload size.
- Verify data handling, logging, and retention behavior.
- Add monitoring for latency, error rate, and cost drift.
- Define fallback routing before broader rollout.
Implementation blueprint
A practical implementation blueprint is to keep rollout incremental. Start with one bounded workflow where output quality is easy to review, such as internal documentation drafting, support reply suggestions, or engineering triage summaries. Keep a human review gate in the loop until the workflow consistently meets your acceptance criteria.
Next, separate experimentation from production routing. Do not replace your existing critical path immediately. Instead, run shadow traffic or side-by-side evaluations where the new stack can be compared directly against your current baseline. This gives your team measurable evidence rather than intuition.
Finally, formalize rollback conditions before launch. If quality drops below target, latency spikes, or costs exceed budget thresholds, the system should route to a known-good fallback provider automatically. This approach keeps adoption fast without sacrificing operational safety.
What to measure in production
Track outcomes at the task level, not just model-level averages. The most useful KPIs are:
- Task completion rate: percent of requests resolved without manual rework.
- First-pass quality score: evaluator or reviewer score on initial outputs.
- Time-to-resolution: end-to-end duration for the workflow, not only model latency.
- Cost per completed task: token and infrastructure cost normalized by successful outcomes.
- Escalation rate: how often a workflow needs human takeover.
Teams that monitor these indicators can identify whether a release creates real leverage or just shifts effort to post-processing and review. A model that looks cheaper per token can still be more expensive if correction overhead increases.
When to defer adoption
Deferring adoption can be the right decision when documentation is incomplete, pricing policy is unstable, or reliability under load is unproven. If your use case is mission-critical and audit-heavy, wait until controls and observability are mature enough to satisfy your governance standards.
A second reason to defer is ecosystem immaturity. If core integrations, tooling libraries, or community-tested patterns are still sparse, early adoption may consume more engineering cycles than it saves. In that case, run a lightweight monthly reassessment and revisit once the ecosystem catches up.
TL;DR
FastAPI + vLLM remains a strong open-source path for production inference APIs when teams need controllable latency, streaming support, and deployment portability. The practical recommendation is to pilot on one measurable workflow first, then scale only if task-completion and cost-per-success beat your current baseline.
Practical recommendation
If you already run Python services, start with FastAPI + vLLM for a controlled pilot before moving to managed inference endpoints. Keep strict SLOs (latency/error/cost), add fallback routing, and ship only after side-by-side results are stable for at least one full business cycle.
Compliance evidence
- Policy evidence: Content includes dated citations, uncertainty framing, no unsupported sensational claims, and practical implementation guidance (AdSense low-value mitigation).
- Author: Charles Jasthyn De La Cueva
- Source-date: 2026-05-01 (compiled); individual source publication/update dates listed below.
- YouTube visual link: Not available — no authoritative, publication-grade official walkthrough video identified for this exact news bundle at publishing time.
Sources
- medium.com — 7 Llm Backends That Actually Work Fastapi Vllm 0621C394E876 — 7 LLM Backends That Actually Work (FastAPI + vLLM) Seven production-ready patterns for serving LLMs from Python — streaming, RAG, tools, routing, and batch — without melting your G
- blog.premai.io — Building A Production Llm Api Server Fastapi Vllm Complete Guide 2026 — Blue-green deployment: run new model alongside old, shift traffic gradually, monitor metrics, roll back if needed. vLLM loads models quickly, so rolling restarts work for non-criti
- dasroot.net — Serving Llms Vllm Fastapi Scale — Serving large language models (LLMs) at scale in 2026 requires efficient infrastructure, with vLLM and FastAPI offering key solutions for performance and scalability</stron
- runpod.io — Serving Phi 2 Cloud Gpu Vllm Fastapi — The model’s smaller size keeps costs low and speed high, while vLLM squeezes out performance, and FastAPI makes it accessible over HTTP. This general pattern can be reused for many
- medium.com — Deploying Llms In Production From Transformers To Vllm And Ollama 80D0Adf4F0Af — Deploying LLMs in Production: From Transformers to vLLM and Ollama In this blog, we’ll walk through three approaches — naive Transformer + FastAPI, the high-performance vLLM infere