
If you are trying to standardize model access in 2026, the hard part is not picking one more model.
It is deciding where the control plane should live.
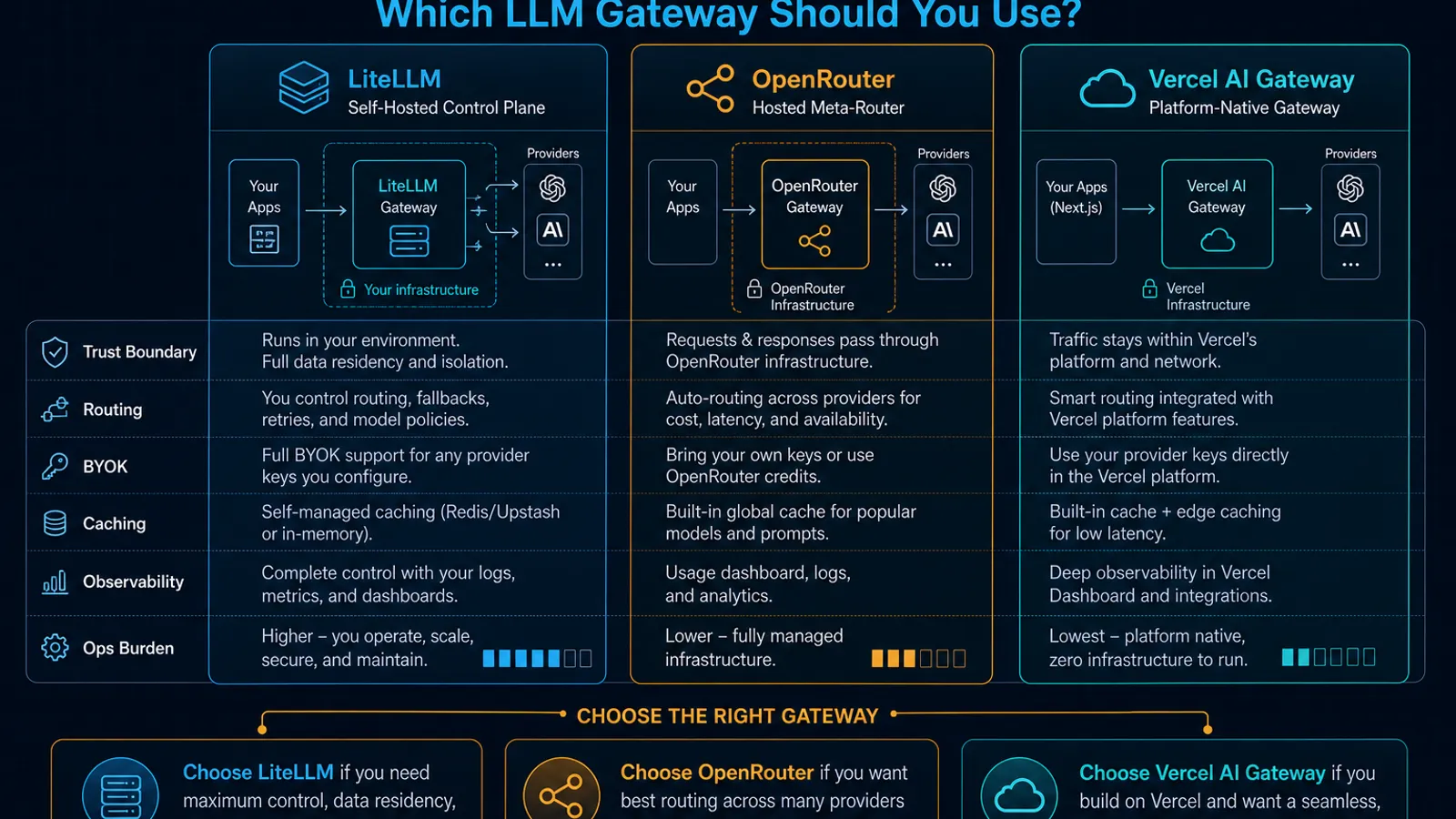
That is the real split between LiteLLM, OpenRouter, and Vercel AI Gateway:
- LiteLLM is strongest when you want to run the gateway yourself and enforce policy inside your own stack.
- OpenRouter is strongest when you want a hosted meta-router with broad model access, provider selection, and privacy controls without operating the gateway.
- Vercel AI Gateway is strongest when your app stack already leans on Vercel and you want routing, logs, spend visibility, and model access in the same platform.
They overlap, but they are not centered on the same job.
As of April 17, 2026, the official docs make the split pretty clear. LiteLLM documents a self-hosted proxy with authentication, virtual keys, multi-tenant spend management, and Docker deployment. OpenRouter documents hosted provider routing, BYOK, prompt-caching-aware sticky routing, and Zero Data Retention controls. Vercel documents a unified gateway with budgets, model fallbacks, provider ordering, BYOK, automatic caching, and built-in observability inside the Vercel dashboard.
If you specifically want the implementation guide for one stack, read How to Use LiteLLM with OpenAI, Claude, and Gemini (2026). This post is the decision framework before that step.
TL;DR
| If your real need is… | Pick | Why |
|---|---|---|
| Run the gateway inside your own trust boundary with platform-team controls | LiteLLM | Its docs are explicit about a self-hosted proxy, auth/authz hooks, virtual keys, spend controls, and per-project customization. |
| Get broad hosted model access and provider routing without operating gateway infrastructure | OpenRouter | Its docs center hosted provider selection, automatic fallbacks, BYOK, caching-aware routing, and privacy controls like ZDR. |
| Stay inside a Vercel-centered app stack with one dashboard for usage, logs, and routing | Vercel AI Gateway | The docs tie gateway access directly to AI SDK, OpenAI-compatible APIs, budgets, fallbacks, and observability views in Vercel. |
| Give app teams a stable OpenAI-style endpoint while a platform team owns policy and keys | LiteLLM | That is the cleanest match for its documented proxy-server posture. |
| Route across many hosted providers while optimizing for uptime and cache behavior | OpenRouter | Provider ordering, fallbacks, and sticky routing are first-class in the docs. |
| Track spend, TTFT, request logs, and model usage by project without adding another observability tool first | Vercel AI Gateway | Vercel documents project- and team-level gateway usage, request logs, TTFT, token counts, and spend charts. |
The real decision: self-hosted control plane, hosted meta-router, or platform-native gateway?
Most comparison posts flatten these products into “one endpoint for many models.”
That is true, but not useful.
The better question is:
Do you want to own the gateway, rent the router, or inherit the gateway from your app platform?
- LiteLLM is the “own the gateway” choice.
- OpenRouter is the “rent the router” choice.
- Vercel AI Gateway is the “inherit the gateway from the platform” choice.
Once you frame it that way, the tradeoffs stop being fuzzy.
LiteLLM is best when the gateway should live inside your stack
LiteLLM’s docs are unusually clear about who the proxy is for.
The official positioning splits LiteLLM into a Python SDK and a Proxy Server, and the proxy is described as a central service (LLM Gateway) for Gen AI enablement / ML platform teams. The documented proxy features include:
- centralized API gateway behavior with authentication and authorization
- multi-tenant cost tracking and spend management per project or user
- per-project customization for logging, guardrails, and caching
- virtual keys for secure access control
- an admin dashboard for monitoring and management
That is not just “use one endpoint for many providers.”
That is a platform ownership story.
The self-hosting posture is also explicit. LiteLLM documents starting the proxy from the CLI, defining models in config.yaml, and running the proxy through Docker with a backing database.
When LiteLLM is the right default
Choose LiteLLM when you need the gateway to behave like internal infrastructure:
- one internal OpenAI-style endpoint for product teams
- provider credentials hidden behind your own service boundary
- project-level budgets and access controls
- the option to attach your own logging, guardrails, and auth hooks
- a deployment path you can run yourself instead of fully outsourcing
This is also the cleanest fit when you want your own trust boundary to be the primary one.
That does not automatically make LiteLLM “more secure” in every environment. It means you own more of the blast radius, key handling, uptime, and patching work. After the recent LiteLLM supply-chain incident, that tradeoff deserves to be treated as operational reality, not branding. See LiteLLM’s PyPI Compromise Is a Worst-Case Supply-Chain Incident for AI Teams.
Where LiteLLM is weaker
LiteLLM is weaker when your team does not want to operate another production control plane.
The docs show real operational surface area:
- config management
- runtime hosting
- database setup
- auth and key lifecycle
- monitoring the proxy itself
If your actual goal is “we just want a hosted routing layer this week,” LiteLLM is usually more work than you want.
OpenRouter is best when you want hosted routing breadth without self-hosting
OpenRouter is easiest to misunderstand if you treat it like just another compatibility shim.
Its docs frame it more like a hosted routing layer that lets you shape which provider endpoint serves a request and under what constraints.
The official docs document:
- provider ordering through
provider.order - automatic fallbacks
- targeting specific provider endpoints and regions
- BYOK with provider keys
- Zero Data Retention enforcement with
zdr: true - prompt-caching-aware sticky routing to maximize cache hits
That combination matters because it means OpenRouter is not just abstracting model names. It is also mediating provider choice, privacy policy, and sometimes cache economics.
What OpenRouter is especially good at
Choose OpenRouter when your main problem is hosted multi-provider access, not internal platform governance.
The strongest use cases are:
- you want access to many hosted providers behind one API key
- you care about provider-specific routing behavior
- you want requests to fall back across providers automatically
- you want per-request privacy constraints like ZDR
- you want prompt caching to stay economically useful across repeated conversations
The prompt caching story is more important than it looks.
OpenRouter’s docs say that after a cached request, the router uses provider sticky routing so later requests for the same conversation stay on the same provider endpoint when that improves cache economics. That is a practical feature for long-context chat and agent workloads, because it prevents “smart routing” from accidentally destroying your cache hit rate.
BYOK on OpenRouter is useful, but not free
OpenRouter’s BYOK docs are also explicit enough to matter in architectural decisions.
The docs say:
- you can route requests through your own provider keys
- keys are securely encrypted and used for requests routed through that provider
- OpenRouter can prioritize your key and fall back according to your settings
- the first 1 million BYOK requests per month are free
- after that, BYOK usage carries a 5% fee of what the same model/provider would normally cost on OpenRouter
That is not necessarily a bad trade.
If BYOK gives you better rate limits, lets you use existing provider credits, and still keeps routing and privacy controls centralized, the fee may be justified. But it is still a real platform cost, not “free abstraction.”
Where OpenRouter is weaker
OpenRouter is weaker when your primary requirement is to keep the control plane inside your own infrastructure or to align tightly with one app platform’s native observability and billing model.
It is also the wrong mental model if what you really wanted was an internal gateway your platform team can customize deeply with your own auth, logging, and policy hooks.
Vercel AI Gateway is best when the gateway should feel native to the app platform
Vercel AI Gateway is not trying to be self-hosted infrastructure, and it is not trying to be a neutral hosted super-router for every possible workflow.
It is trying to make model access, routing, and visibility feel like part of the Vercel application stack.
The official docs say AI Gateway provides:
- one endpoint for hundreds of models
- budgets, usage monitoring, load balancing, and fallbacks
- compatibility with AI SDK, OpenAI Chat Completions, OpenAI Responses, and Anthropic Messages
- BYOK support
- no markup on tokens, including with BYOK
The more distinctive part is what Vercel adds around that gateway.
Its provider-options docs include:
- provider ordering and filtering
- automatic caching with
caching: 'auto' - model fallbacks
- per-provider timeouts for fast failover
- request-scoped BYOK
And its observability docs expose:
- request counts by model
- time to first token
- input and output token counts
- spend over time
- request logs grouped by project and API key
That is a very specific kind of value.
It is less about “we need the broadest router on the market” and more about “we want gateway operations to show up in the same place as the rest of our shipping workflow.”
When Vercel AI Gateway is the right default
Choose Vercel AI Gateway when:
- your frontend or API stack already lives on Vercel
- your team already uses AI SDK or Vercel-native app workflows
- you want model access, spend controls, and request logs without assembling a separate gateway-plus-observability stack first
- project-level visibility matters more than self-hosting purity
This is also why Vercel AI Gateway makes sense for coding-tool workflows. Vercel now explicitly documents routing coding agents through AI Gateway so teams can consolidate spend tracking, fallbacks, and request visibility in one place.
If that angle matters, read Claude Opus 4.6 Fast Mode on Vercel AI Gateway: What Changed and When It Is Worth It.
Where Vercel AI Gateway is weaker
Vercel AI Gateway is weaker when you want the gateway to be a standalone, self-run control plane or when your architecture is deliberately platform-agnostic.
It can still be used through OpenAI-compatible clients, but the product value is most coherent when you actually want the Vercel coupling instead of trying to avoid it.
The comparison that actually matters
1. Hosting model
- LiteLLM: self-hosted proxy is a core part of the product story.
- OpenRouter: hosted router; your leverage comes from routing and policy features, not running the control plane yourself.
- Vercel AI Gateway: hosted gateway that is meant to sit inside the Vercel platform surface.
If “where does this service run?” is your first security or procurement question, LiteLLM is the obvious outlier.
2. Routing and failover
- LiteLLM documents retry and fallback logic plus router behavior, but the real advantage is that the routing layer is yours.
- OpenRouter is strongest on provider-centric hosted routing behavior: ordered providers, automatic fallbacks, endpoint targeting, and ZDR-aware selection.
- Vercel AI Gateway is strongest when you want provider ordering, model fallbacks, and provider timeouts inside a Vercel-native flow.
If routing policy itself is the product you are buying, OpenRouter is the cleanest hosted answer.
3. Governance and key control
- LiteLLM emphasizes auth/authz, virtual keys, and multi-tenant spend management.
- OpenRouter emphasizes BYOK plus routing and privacy policies.
- Vercel AI Gateway emphasizes request-scoped BYOK, budgets, and dashboard-level usage controls.
If you want internal gateway governance, LiteLLM wins. If you want hosted key aggregation and provider choice, OpenRouter is stronger. If you want app-project governance in the same place as deployment telemetry, Vercel fits better.
4. Caching behavior
- LiteLLM documents caching as part of per-project customization, but the public docs are less opinionated about cache strategy at the routing layer.
- OpenRouter has the most explicit routing-aware caching story, especially provider sticky routing after cached requests.
- Vercel AI Gateway documents automatic caching behavior in the gateway layer for providers that need explicit cache markers.
If prompt caching is central to your economics, OpenRouter and Vercel are the ones with the clearest gateway-level behavior documented today.
5. Observability
- LiteLLM gives you dashboard and callback options, but you are still closer to building your own final observability stack.
- OpenRouter gives you activity and privacy controls, but the product center is still routing.
- Vercel AI Gateway has the most explicit built-in request, spend, TTFT, and project/API-key views in the platform docs.
If your next question after “which model?” is “who spent what, where did latency spike, and which project caused it?”, Vercel has the sharpest out-of-the-box answer.
For a broader observability decision framework, read Langfuse vs Phoenix vs Helicone (2026): Choosing an LLM Observability Stack and LLM Tracing Without Lock-In: A Practical OpenTelemetry Stack.
So which one should you actually choose?
Pick LiteLLM if:
- you want the gateway inside your own infrastructure
- platform teams need to own access, budgets, and gateway behavior directly
- a self-hosted proxy is a feature, not a burden
Pick OpenRouter if:
- you want the fastest hosted path to many providers
- provider routing policy and privacy controls matter
- you do not want to operate the gateway yourself
Pick Vercel AI Gateway if:
- your app stack already lives on Vercel
- you want gateway metrics and routing controls in the same platform
- AI SDK and Vercel-native workflows are part of the point, not an incidental detail
The practical bottom line
This is not a contest with one universal winner.
It is a control-boundary decision.
- LiteLLM is the best fit when the gateway is internal platform infrastructure.
- OpenRouter is the best fit when the router itself is a hosted service you want to leverage aggressively.
- Vercel AI Gateway is the best fit when model routing should feel native to the Vercel application platform.
If you choose based on that boundary first, the rest of the feature matrix gets much easier.
If you choose based on a vague promise of “one API for all models,” you will probably end up redoing the decision after your first real traffic spike, budget fight, or compliance review.
SEO FAQ
Which LLM gateway is best for self-hosting?
LiteLLM is the best fit when the gateway should run inside your own infrastructure with your own access controls, budget rules, logging, and platform ownership.
Which LLM gateway is best for hosted provider routing?
OpenRouter is the strongest fit when broad hosted model access, provider routing, BYOK, privacy controls, and prompt-caching-aware routing are the primary needs.
Which LLM gateway is best for Vercel apps?
Vercel AI Gateway is the strongest fit when the application already uses Vercel and the team wants request logs, spend visibility, fallbacks, and model routing in the same platform surface.
When to Use
Use this comparison when the decision is really about gateway ownership. It is strongest before a platform team chooses whether to self-host LiteLLM, rely on OpenRouter for hosted provider routing, or keep gateway operations inside a Vercel-centered app workflow.
When Not to Use
Do not use this as a final compliance answer by itself. The right gateway still depends on your data boundary, provider contracts, retention requirements, incident process, and who will own uptime when routing fails.