IBM Think 2026 is a useful signal because it treats enterprise AI as an operating-model problem, not only as a model or chatbot problem.
IBM’s announcement frames the next stage around planning, building, deploying, and governing AI agents at scale. It also points to a broader stack: watsonx Orchestrate for multi-agent orchestration, IBM Confluent for real-time data, IBM Concert for intelligent operations, and IBM Sovereign Core for operational independence.
That combination is the real story.
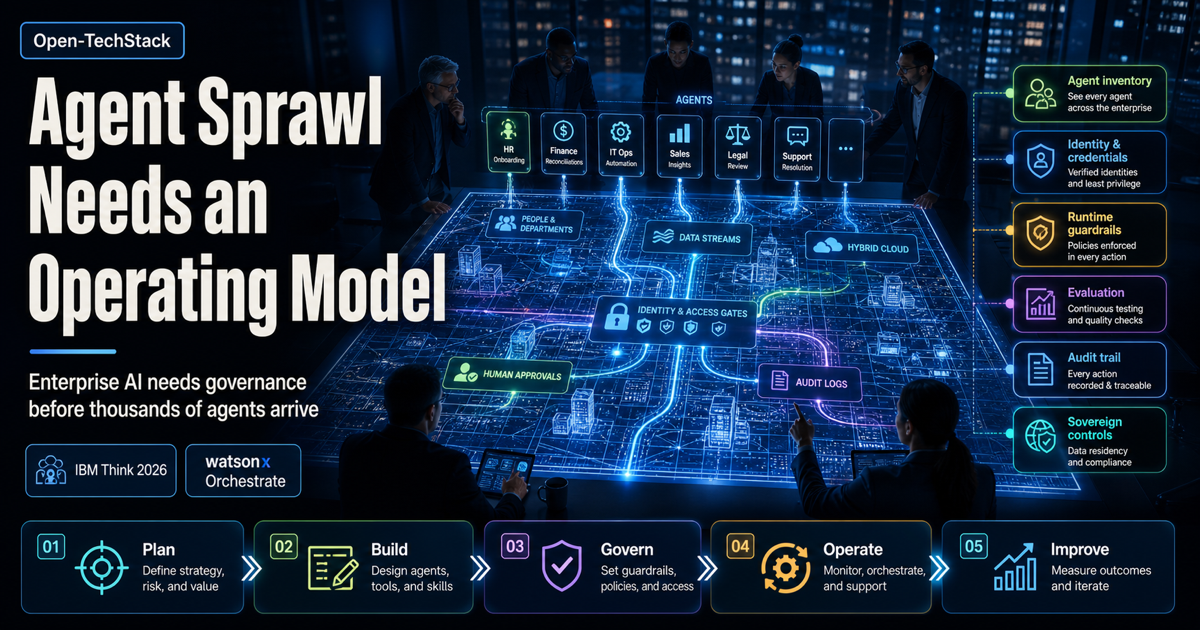
Enterprises are no longer asking whether an agent can complete a demo. They are asking whether hundreds or thousands of agents can run across departments without creating security drift, duplicated automation, invisible costs, and untraceable decisions.
The sharper question is: does the organization have an operating model for agents before agent sprawl becomes another unmanaged software estate?
This is independent Open-TechStack analysis. It is not official IBM guidance, legal advice, procurement advice, or a sponsored post.
TL;DR
IBM Think 2026 matters because it pushes the conversation from building individual agents to operating an agent ecosystem.
- IBM describes Think 2026 as a blueprint for an AI operating model as the “AI divide” widens.
- IBM announced a next-generation watsonx Orchestrate for multi-agent orchestration.
- IBM’s product page describes watsonx Orchestrate as an agentic control plane for scaling and governing AI.
- IBM says the control-plane idea is open, integrated, trusted, and hybrid, so enterprises can work with agents, tools, systems, cloud, and on-premises environments.
- IBM’s Think recap says only 18% of organizations maintain a current and complete AI inventory.
- The same recap says building agents is only about 20% of the agent development lifecycle; most of the lifecycle is testing, deploying, operating, and monitoring agentic systems in production.
- The practical lesson: the enterprise bottleneck is not agent creation. It is agent governance, integration, observability, and lifecycle control.
If your team is already thinking about agent routing, pair this with yesterday’s AI Gateway routing playbook. If your agents are touching tools or repositories, also read the AI agent observability stack.
What changed
IBM’s Think 2026 announcement is broad, but the agent takeaway is specific: enterprises need a way to manage AI-driven systems with the same rigor they expect from core business systems.
The company announced capabilities across four connected areas:
| Area | Why it matters for agents |
|---|---|
| Multi-agent orchestration | Agents need to coordinate across workflows, not live as isolated demos. |
| Real-time, AI-ready data | Agents need governed, current context before they can act reliably. |
| Hybrid cloud management | Agents will run near applications, infrastructure, security, and operations, not only in one SaaS surface. |
| Governance and sovereignty | Enterprises need policy, auditability, residency, and operational independence. |
The useful part is the framing. IBM is not just saying “build more agents.” It is saying enterprises need a repeatable way to plan, build, deploy, and govern them.
That framing fits what production teams are already discovering. Agents are easy to prototype, but hard to operate when they cross identity systems, data platforms, approval chains, customer records, internal tools, and compliance boundaries.
Why agent sprawl is different from app sprawl
Traditional app sprawl is already painful: duplicated tools, unclear ownership, inconsistent security, redundant subscriptions, and shadow IT.
Agent sprawl adds a more active risk.
An agent may not only store information. It may decide what to retrieve, which tool to call, what record to update, who to notify, which code to write, which ticket to close, or which exception to escalate. Even if every individual agent seems useful, the ecosystem can become ungovernable if the organization cannot answer basic questions:
- Which agents exist?
- Who owns each one?
- Which tools and data sources can each agent reach?
- Which credentials does it use?
- Which actions require human approval?
- Which model, route, or runtime does it depend on?
- What logs prove what happened?
- What happens when the agent fails, drifts, or becomes obsolete?
IBM’s Think recap points directly at this gap by citing AI inventory as a weak spot. If an enterprise cannot maintain a current inventory, it cannot govern risk, cost, quality, or reuse.
The operating model enterprises need
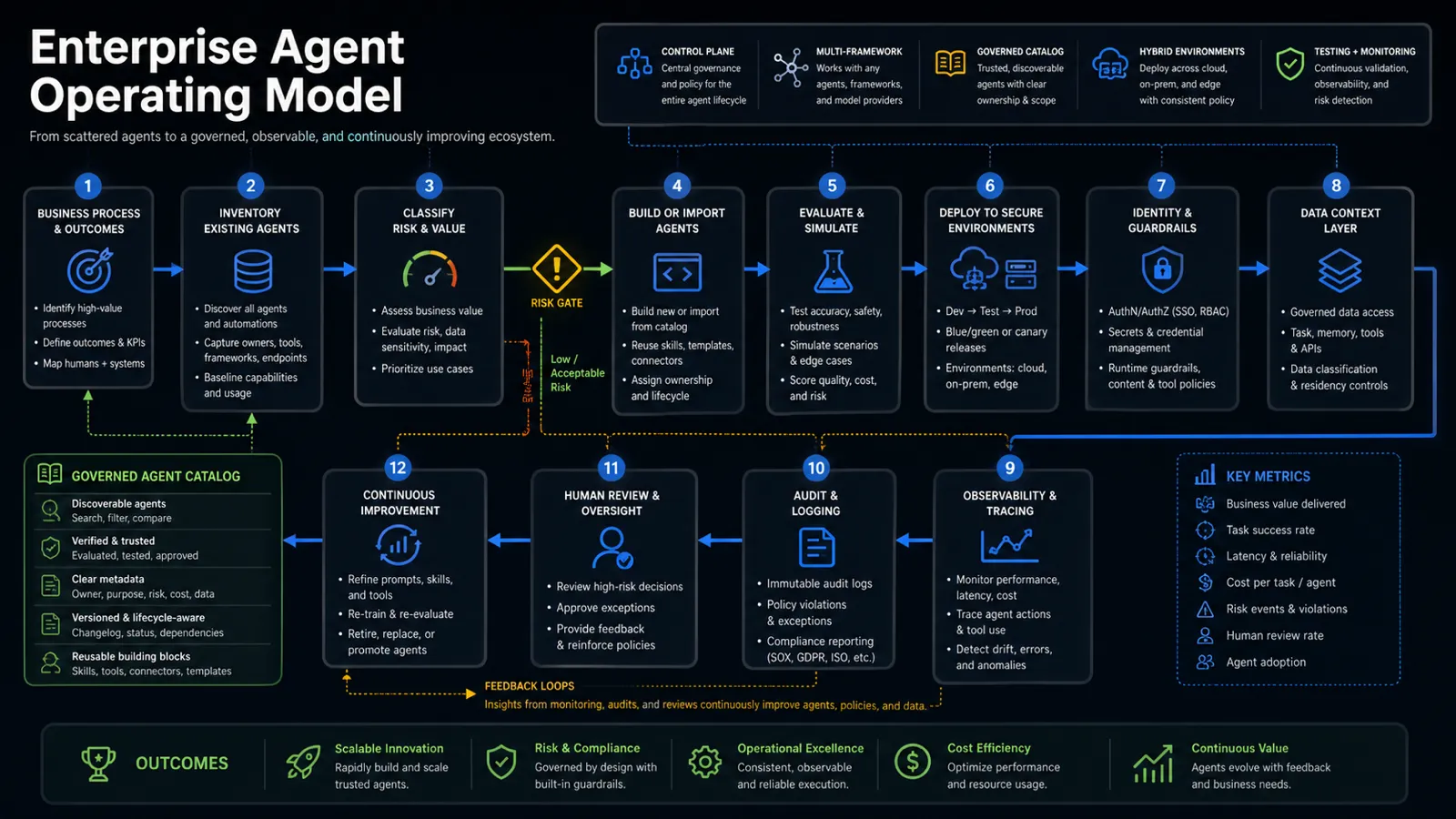
An enterprise agent operating model should be boring enough to run every week.
It does not need to start as a massive transformation program. It needs a small number of rules that turn agents from scattered experiments into managed assets.
Use this first version:
| Operating layer | Minimum requirement |
|---|---|
| Inventory | Every agent has an owner, purpose, runtime, model route, tools, data sources, and risk tier. |
| Intake | New agents must map to a business process, expected outcome, and success metric. |
| Build | Teams can use no-code, pro-code, vendor-built, or third-party agents, but each must enter the same catalog. |
| Evaluation | Agents are tested for task success, safety, latency, cost, privacy, and failure behavior before rollout. |
| Deployment | Agents move through dev, test, and production with environment-specific controls. |
| Identity | Agents use scoped credentials, least privilege, rotation, and secret handling. |
| Runtime policy | Guardrails enforce allowed tools, approvals, rate limits, content rules, and data boundaries. |
| Observability | Logs capture prompts, tool calls, latency, token usage, cost, errors, and outcomes. |
| Audit | High-risk decisions and state-changing actions are traceable and reviewable. |
| Lifecycle | Agents can be improved, paused, retired, replaced, or merged when business needs change. |
That is the difference between agent adoption and agent operations.
How to classify agent risk
Not every agent needs the same controls. A meeting-summary agent and a finance-reconciliation agent should not go through identical review.
Start with four tiers:
| Tier | Example | Control level |
|---|---|---|
| Informational | summarizing public docs, drafting internal notes | light logging, owner, basic evaluation |
| Internal workflow | updating tickets, preparing reports, routing support cases | tool allowlist, business-owner approval, latency and quality checks |
| Sensitive data | working with customer records, HR, finance, security logs | scoped identity, data classification, audit logs, privacy review |
| High-impact action | changing production systems, financial actions, legal decisions, access changes | human approval, rollback path, strict audit, incident response plan |
This is where IBM’s “control plane” framing is useful. Enterprises do not need every agent decision to be manual. They need a place where policy can be defined, enforced, monitored, and changed.
Without that layer, every department becomes its own agent platform.
What not to do
Do not let every team buy or build agents independently and promise to clean it up later.
That creates the worst version of enterprise AI: fast local wins, slow global risk. The marketing team gets an agent, finance gets an agent, IT operations gets an agent, customer support gets an agent, and six months later nobody can explain who owns credentials, where logs live, what data crosses boundaries, or which agents are still active.
Also avoid these patterns:
- treating an agent catalog as governance by itself
- skipping inventory because the first few agents feel low risk
- letting agents share broad service accounts
- approving tool access without data classification
- measuring only productivity while ignoring errors, exceptions, and rework
- deploying agents without an owner and retirement path
- using one governance process for both harmless drafts and high-impact actions
Agent governance should not be theater. It should remove friction from safe work while slowing down risky work in a visible way.
Copy this checklist before scaling agents
Before an enterprise scales agent adoption, the platform owner should be able to answer:
- Do we have a complete inventory of agents, owners, tools, data sources, and runtimes?
- Can every agent be tied to a business process and measurable outcome?
- Which agents are informational, workflow-changing, sensitive-data, or high-impact?
- Which credentials does each agent use, and who approves access changes?
- Which data classifications and residency rules apply?
- Which tools are allowed, blocked, or approval-gated?
- How do we test agents before production?
- What logs show tool calls, model calls, errors, latency, cost, and user impact?
- Which alerts detect drift, policy violations, or abnormal tool use?
- Who can pause, rollback, or retire an agent?
- What is the review cadence for stale, duplicated, or underperforming agents?
If those answers live in scattered spreadsheets and chat threads, the operating model is not ready yet.
FAQ
What is an AI agent operating model?
An AI agent operating model is the set of processes, controls, ownership rules, tools, and metrics an organization uses to plan, build, deploy, monitor, govern, and improve AI agents across the enterprise.
What is watsonx Orchestrate?
IBM describes watsonx Orchestrate as an agentic control plane for scaling and governing AI. Its product materials emphasize bringing an agent ecosystem into one operational layer with visibility, policy enforcement, lifecycle control, integration, and hybrid deployment options.
Is an agent catalog enough?
No. A catalog helps teams find and reuse agents, but it is not enough by itself. Enterprises also need identity controls, runtime policies, evaluation, observability, audit logs, business ownership, and lifecycle management.
Why does agent inventory matter?
Inventory is the foundation for governance. If a company does not know which agents exist, it cannot reliably manage access, risk, data usage, cost, quality, or retirement.
Bottom line
IBM Think 2026 is another sign that the enterprise AI conversation is moving beyond pilots.
The next competitive edge will not come from creating the most agents. It will come from operating agents safely across real business systems: with inventory, governed data, scoped identity, observability, audit trails, and continuous improvement.
Build agents if they solve real problems. But build the operating model before agent sprawl becomes the new shadow IT.