GitHub Repos for Multimodal OCR and Doc Intelligence is a high-impact topic because repository choice determines your long-term velocity, not just your first prototype. In RAG systems, weak repo selection often causes hidden operational costs: brittle ingestion flows, poor observability, weak evaluation, and difficult upgrades. Strong repository choices, on the other hand, compress delivery time and reduce failure rates across the entire lifecycle.
This guide focuses on free and open-source repositories and gives you a practical path from shortlist to production. The goal is not to copy a trend list; it is to choose tools that match your architecture constraints, team skill level, and reliability requirements.
TL;DR
- Choose repositories by production fit, not stars alone.
- Enforce measurable gates: retrieval quality, latency, and rollback readiness.
- Pilot with one real workflow for 30 days before broad rollout.
Practical recommendation
Start with one workflow and one owner, then run a 30-day scorecard using explicit targets (accuracy, latency, cost, failure rate). Promote repos only if they pass operational gates in your environment.
What to evaluate before selecting repos
Use these criteria when shortlisting repositories for RAG pipelines:
- Pipeline coverage: ingestion, chunking, retrieval, generation, and evaluation support.
- Operational readiness: logging, retries, error handling, and maintainability.
- Ecosystem health: release activity, issue responsiveness, and community adoption.
- Interoperability: compatibility with your vector DB, model serving layer, and orchestration stack.
- Governance fit: license clarity, security posture, and reproducible deployment patterns.
If a repo scores high in demos but low in operations, treat it as experimental and isolate it from critical workloads.
Best GitHub repositories to start with
| # | Repository | Why it belongs in a RAG stack |
|---|---|---|
| 1 | PRITHIVSAKTHIUR/Multimodal-OCR | Built upon a diverse ecosystem of cutting-edge vision-language models—including architectures based on Qwen2.5-VL, Qwen2-VL, and Cohere’s Aya-Vision—this application excels at |
| 2 | Yuliang-Liu/MultimodalOCR | This is the repository of the OCRBench & OCRBench v2. OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and |
| 3 | mindee/doctr | Your API should now be running locally on your port 8002. Access your automatically-built documentation at http://localhost:8002/redoc and enjoy your three functio |
| 4 | Topdu/OpenOCR | OpenOCR aims to build a comprehensive open-source ecosystem for General-OCR, bridging academic research and real-world applications, and fostering the collaborative development and |
| 5 | leokhoa/Open-DocLLM | The integration of OCR and LLM technologies in this project marks a pivotal advancement in analyzing unstructured data. The combination of open-source projects like Tesseract and M |
| 6 | rednote-hilab/dots.ocr | 2025.07.30 🚀 We release dots.ocr, — a multilingual documents parsing model based on 1.7b llm, with SOTA performance. |
These repositories are complementary rather than mutually exclusive. Many strong stacks combine an orchestration framework, an evaluation toolkit, and a gateway/routing layer for model resilience.
Reference architecture for a repository-first RAG stack
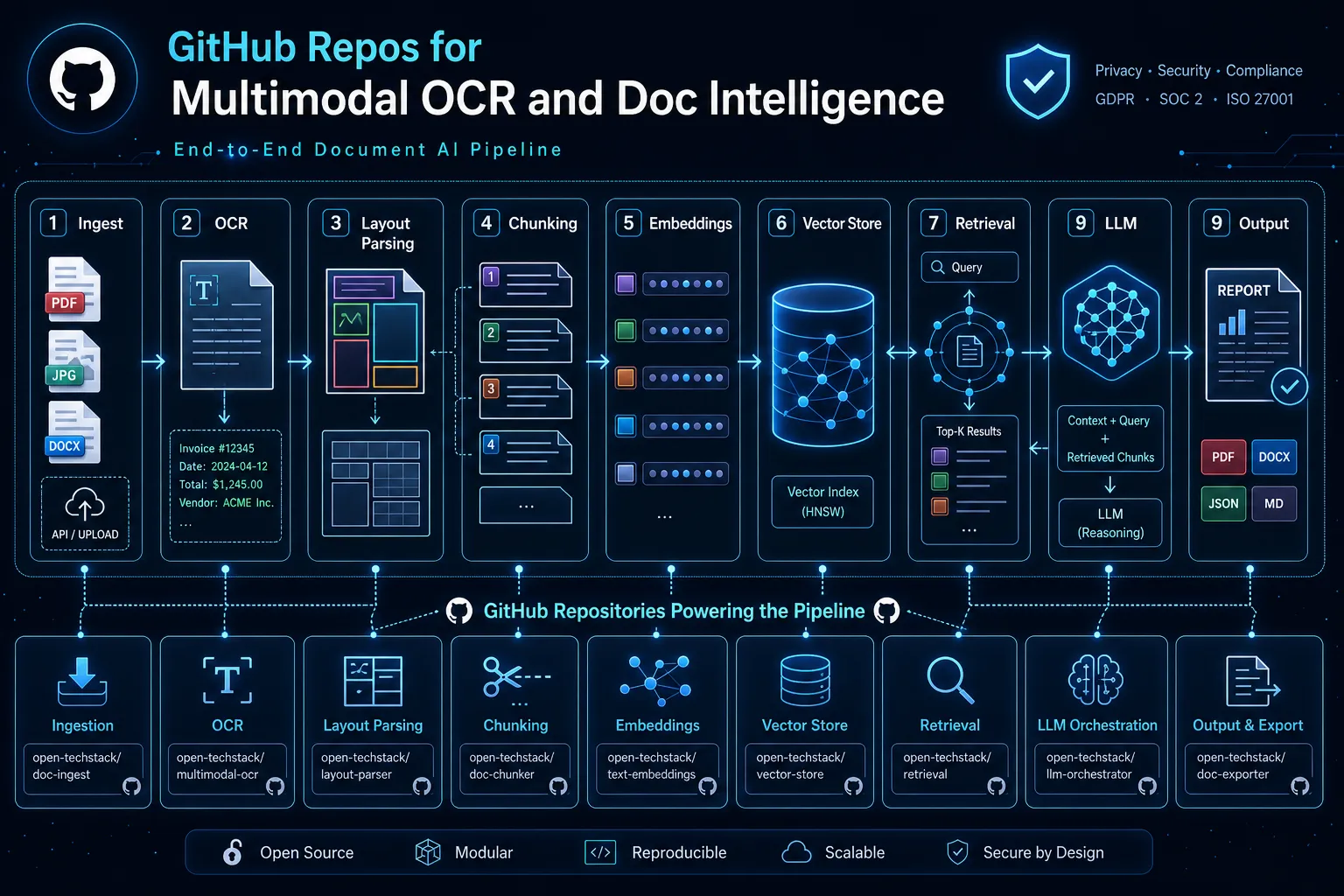
A resilient architecture usually follows this flow:
- Ingestion layer: loaders + normalization + document versioning.
- Indexing layer: chunking strategy + embeddings + vector storage.
- Retrieval layer: hybrid retrieval, reranking, context assembly.
- Generation layer: model routing, fallback policy, output constraints.
- Evaluation layer: faithfulness/relevance metrics and regression checks.
Keep each layer modular. The easiest way to avoid lock-in is to define clear interfaces between retrieval, generation, and evaluation.
Step-by-step walkthrough
Step 1 — Build a minimal vertical slice
Implementation plan (from zero to reliable)
Step 1 — Build a minimal vertical slice
Pick one real workflow (for example, policy Q&A, repository assistant, or support triage). Build a vertical slice that goes end-to-end from ingestion to answer output. Avoid multi-domain scope in the first week.
Step 2 — Add observability early
Add request tracing, prompt/context logs, and retrieval diagnostics before broad rollout. If a team cannot explain why a bad answer happened, improvement loops become guesswork.
Step 3 — Add evaluation gates
Use automated checks for retrieval relevance and answer faithfulness. A lightweight evaluation gate before deployment prevents silent quality drift.
Step 4 — Introduce fallback routing
Add at least one fallback model/provider path so transient outages do not stop your pipeline. Route failures gracefully and monitor fallback frequency as a quality signal.
Step 5 — Harden operations
Define runbooks for reindexing, schema migration, rollback, and incident response. Most production incidents are operational, not theoretical-model failures.
Common mistakes and how to avoid them
- Choosing by stars alone: stars indicate popularity, not operational fitness.
- Skipping evaluation: without metrics, quality regressions are discovered too late.
- Over-indexing context: larger context windows do not fix weak retrieval.
- Ignoring versioning: unversioned embeddings and indexes break reproducibility.
- Treating costs per token as total cost: include engineering and incident overhead.
30-day production readiness checklist
- Define baseline KPIs: task completion rate, first-pass quality, and cost per resolved task.
- Verify at least one fallback route and one rollback strategy.
- Stress-test malformed data, empty retrieval results, and long-context edge cases.
- Confirm logging and access controls for compliance-sensitive data.
- Lock dependency versions and document upgrade strategy.
Sources
- github.com — GitHub - PRITHIVSAKTHIUR/Multimodal-OCR: Multimodal-OCR is an experimental, high-performance
- github.com — GitHub - Yuliang-Liu/MultimodalOCR: On the Hidden Mystery of OCR in Large Multimodal Models
- github.com — GitHub - mindee/doctr: docTR (Document Text Recognition) - a seamless, high-performing & acc
- github.com — GitHub - Topdu/OpenOCR: OpenOCR: An Open-Source Toolkit for General-OCR Research and Applica
- github.com — GitHub - leokhoa/Open-DocLLM · GitHub
- github.com — GitHub - rednote-hilab/dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Lan
Related posts
Screenshots