
TL;DR
Gemma 4 is the kind of launch that matters most when you think in workflows instead of benchmarks.
Google’s release log lists Gemma 4 on March 31, 2026, and the launch post landed on April 2, 2026. The headline is simple: Google says this is its most capable open model family yet, and it is explicitly aimed at advanced reasoning, agentic workflows, code generation, and on-device deployment. (Google AI for Developers, Google DeepMind)
If you were searching for “what is Gemma 4” or “where does Gemma 4 fit,” the short answer is:
- it is an open model family, not a single checkpoint
- it ships in multiple sizes for different hardware targets
- it is useful when the model needs to live close to the app, the device, or the codebase
- it is less interesting if you just want a hosted model and do not want to think about runtime choices
That makes Gemma 4 a developer tool story as much as a model story.
What Google actually released
Google says Gemma 4 comes in four sizes:
- E2B
- E4B
- 26B Mixture of Experts
- 31B Dense
The launch post says the family moves beyond plain chat and is built for complex logic and agentic workflows. It also says all models support video and image input, the smaller E2B and E4B models add native audio input, and the family supports 140+ languages. Google lists 128K context for the edge models and up to 256K for the larger models. (Google DeepMind)
The practical detail that matters is not just scale. It is packaging.
Gemma 4 is released under Apache 2.0, which means Google is trying to make the family broadly usable across commercial products, internal tools, and experimental work. That is a different posture from a closed hosted API. It gives teams room to run, adapt, and deploy the model on their own terms. (Google DeepMind)
Why developers should care
Most model launches promise “more intelligence.” Gemma 4 is more specific.
Google’s framing points to three practical use cases:
1. Local-first coding and assistant workflows
Google says Gemma 4 supports high-quality offline code generation and can power IDEs, coding assistants, and agentic workflows on consumer GPUs and workstations. That makes it a relevant option if you are building around local runtimes instead of relying on a hosted model for every prompt. (Google DeepMind)
If your stack already leans local, this sits naturally next to tools like Ollama vs LM Studio (2026): Which Should You Use to Run Local LLMs? and terminal-centric agent workflows like GitHub Copilot CLI BYOK and Local Models: What Changed and Why It Matters.
2. Agentic workflows that need structure, not just generation
Google says Gemma 4 includes native support for function calling, structured JSON output, and system instructions. That is the difference between “the model can answer questions” and “the model can reliably sit inside a tool loop.” (Google DeepMind)
That matters for:
- workflow automation
- internal copilots
- retrieval-heavy apps
- assistants that have to call APIs rather than improvise around them
If you are still designing your stack, this is a good moment to keep the agent boundary explicit. The model is part of the system, not the system itself.
3. Edge and on-device deployment
Gemma 4’s E2B and E4B sizes are the clearest sign that Google wants this family to run close to hardware constraints. The launch post says the smaller models are optimized for phones, Raspberry Pi, and NVIDIA Jetson Orin Nano, and it points Android developers toward AICore Developer Preview for forward compatibility with Gemini Nano 4. (Google DeepMind)
That gives app teams a few concrete paths:
- run models locally for privacy-sensitive features
- keep latency low for interactive experiences
- prototype on-device AI before you commit to server-side inference
If you build mobile or edge software, that is the most interesting part of the release. It is not just “smaller model.” It is a model family designed for deployment constraints you actually meet in production.
Where Gemma 4 fits in a real workflow
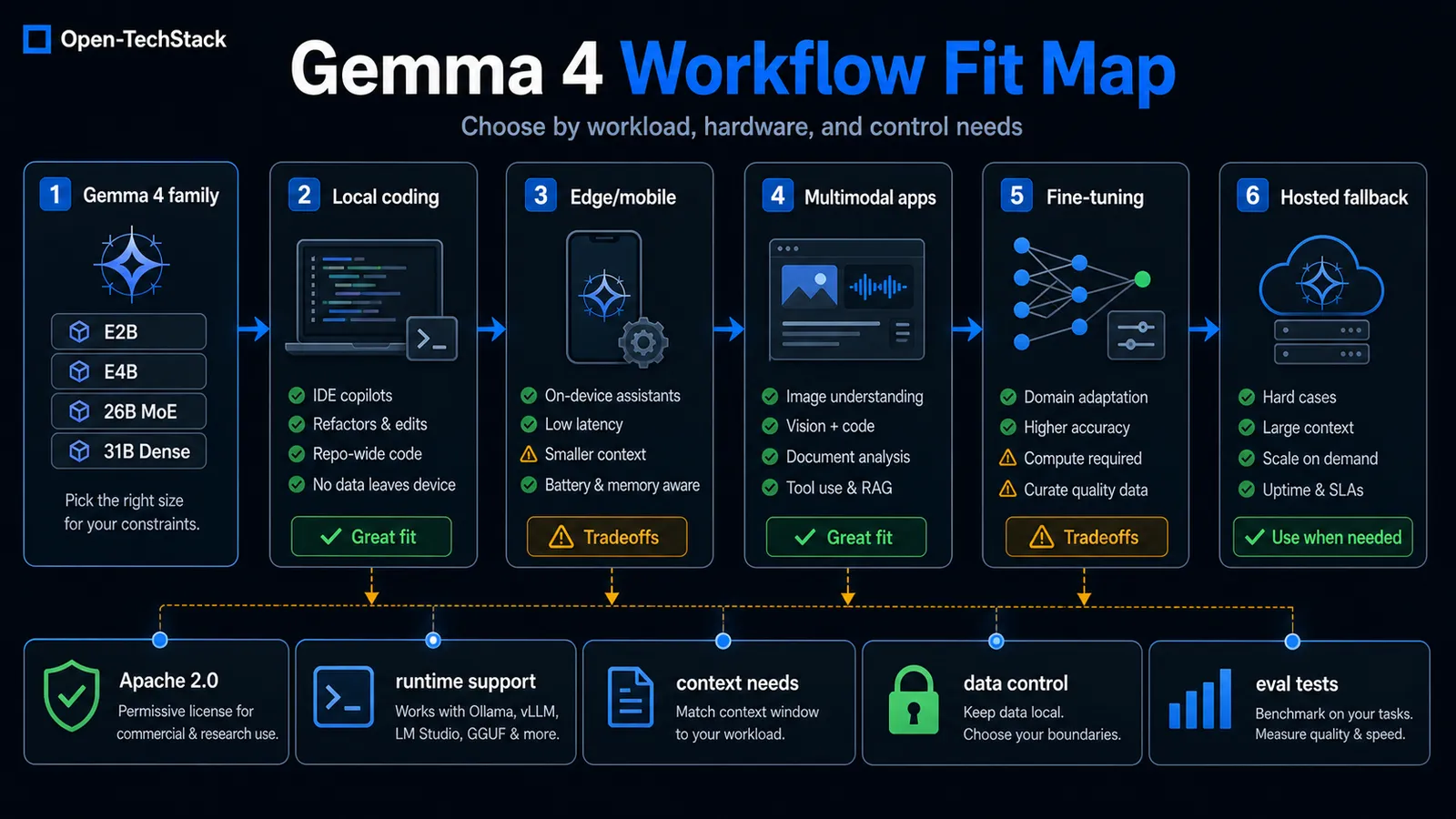
Use Gemma 4 when you need one or more of these things:
- a permissively licensed model you can deploy yourself
- a model that can handle multimodal inputs without jumping to a large hosted service
- a local code assistant that is not just a toy demo
- a model that can power structured tool use
- a deployable path from laptop to workstation to edge device
| Workflow need | Gemma 4 fit | What to check first |
|---|---|---|
| Local coding assistant | Strong fit when privacy, latency, or offline use matters | IDE integration, quantization path, repo-context limits, eval set |
| Edge or mobile feature | Strong fit for constrained on-device prototypes | memory budget, battery impact, AICore or local runtime support |
| Multimodal app | Useful when image, video, or audio input belongs close to the product | supported input modes, prompt format, latency, fallback model |
| Fine-tuned internal model | Useful when the team needs domain adaptation and model ownership | training data quality, licensing, evals, deployment pipeline |
| Hosted AI product | Weaker fit if operations want a managed API only | hosted fallback, uptime requirements, provider abstraction |
That makes it a strong fit for:
- internal developer tools
- local-first AI assistants
- on-device product features
- prototype agent loops
- multimodal document or screenshot workflows
It also maps cleanly to teams that want to fine-tune and adapt models rather than consume them as a fixed API. Google explicitly says Gemma 4 is sized to run and fine-tune efficiently across hardware, and the launch post points developers to tools like Hugging Face, LiteRT-LM, vLLM, llama.cpp, MLX, Ollama, and Vertex AI. (Google DeepMind)
If you are building around post-training, this is adjacent to Unsloth Studio: The No-Code UI That Makes Local LLM Training Actually Accessible, but the jobs are different. Unsloth Studio is about making fine-tuning easier. Gemma 4 is about giving you a stronger base model family to tune and deploy.
Where it does not fit as cleanly
Gemma 4 is not automatically the right answer just because it is open.
It is a weaker fit when:
- you want a fully managed hosted model and do not want to think about GPUs, quantization, or runtime support
- your app needs a provider-agnostic API more than a downloadable model family
- your team does not have a deployment path for local or edge inference
- you only need plain chat and do not benefit from multimodal or tool-calling features
That is the hidden tradeoff in a launch like this. Open models reduce dependence on a vendor, but they increase your responsibility for the runtime.
The practical read
The release signal here is not that Google shipped another model family.
It is that Google is pushing open models into the places where teams actually build products:
- local workstations
- developer laptops
- mobile devices
- embedded devices
- agent workflows
- multimodal apps
That makes Gemma 4 relevant for more than benchmark watching. It is a credible base layer for teams that want open weights, structured outputs, multimodal input, and a deployment story that reaches beyond a hosted prompt box.
For most developers, the question is not whether Gemma 4 is impressive. Google’s own launch materials make that easy to answer.
The real question is whether your workflow benefits from a model family you can run, adapt, and place closer to the problem.
If the answer is yes, Gemma 4 is worth attention.
When to Use
Use Gemma 4 when open weights, local deployment, edge experimentation, or controllable model behavior matter more than buying the highest possible hosted benchmark score. It is especially relevant for prototypes that need to move from laptop to mobile or embedded environments.
When Not to Use
Do not evaluate Gemma only as a “small model versus frontier model” story. Its practical value depends on whether your workload benefits from open weights, local deployment, lower cost, and tighter control over data handling.
If your team needs maximum reasoning quality, heavy tool orchestration, or enterprise-grade hosted support, a larger hosted model may still be the better default. Gemma is strongest when ownership, portability, and experimentation matter more than raw ceiling.
SEO FAQ
What is Gemma 4?
Gemma 4 is Google’s open model family aimed at developers who want models they can run, adapt, and deploy across local, edge, multimodal, and agentic workflows.
Is Gemma 4 open source?
Google describes Gemma 4 as an open model family released under Apache 2.0. Teams should still review the model terms, licensing details, and deployment requirements before using it in a product.
When should developers use Gemma 4 instead of a hosted model?
Use Gemma 4 when local execution, data control, low latency, fine-tuning, edge deployment, or runtime ownership matters more than the convenience of a fully managed hosted API.
Is Gemma 4 a replacement for frontier hosted models?
Not always. A hosted frontier model may still be better for maximum reasoning quality, managed uptime, broad enterprise support, or workloads that do not need local or edge deployment.
What should teams evaluate before adopting Gemma 4?
Teams should test runtime support, hardware fit, context needs, multimodal behavior, data-control requirements, quality on their own eval set, and fallback behavior for tasks Gemma 4 does not handle well.