
TL;DR
“Just stuff it in the context window” is the new “just add a vector database.”
In 2026, long-context models are genuinely useful — but they do not eliminate retrieval. They just change the boundary: what can live in the prompt versus what must live in a queryable store.
For example, OpenAI’s GPT‑5.4 documentation describes a 1,050,000 token context window. That is huge — but it still behaves like a working set, not a perfect memory.
This post is a practical decision framework for builders choosing between:
- Long context (big prompts, minimal infra)
- RAG (retrieval + grounding over a corpus)
- Hybrid (retrieve first, then use long context as the working set)
If you’re coming from the “agent workflows” angle, this connects directly to long-context hygiene and guardrails: GPT-5.4 Is Here: A Developer Playbook for Faster, Safer Agents.
The one-line decision rule
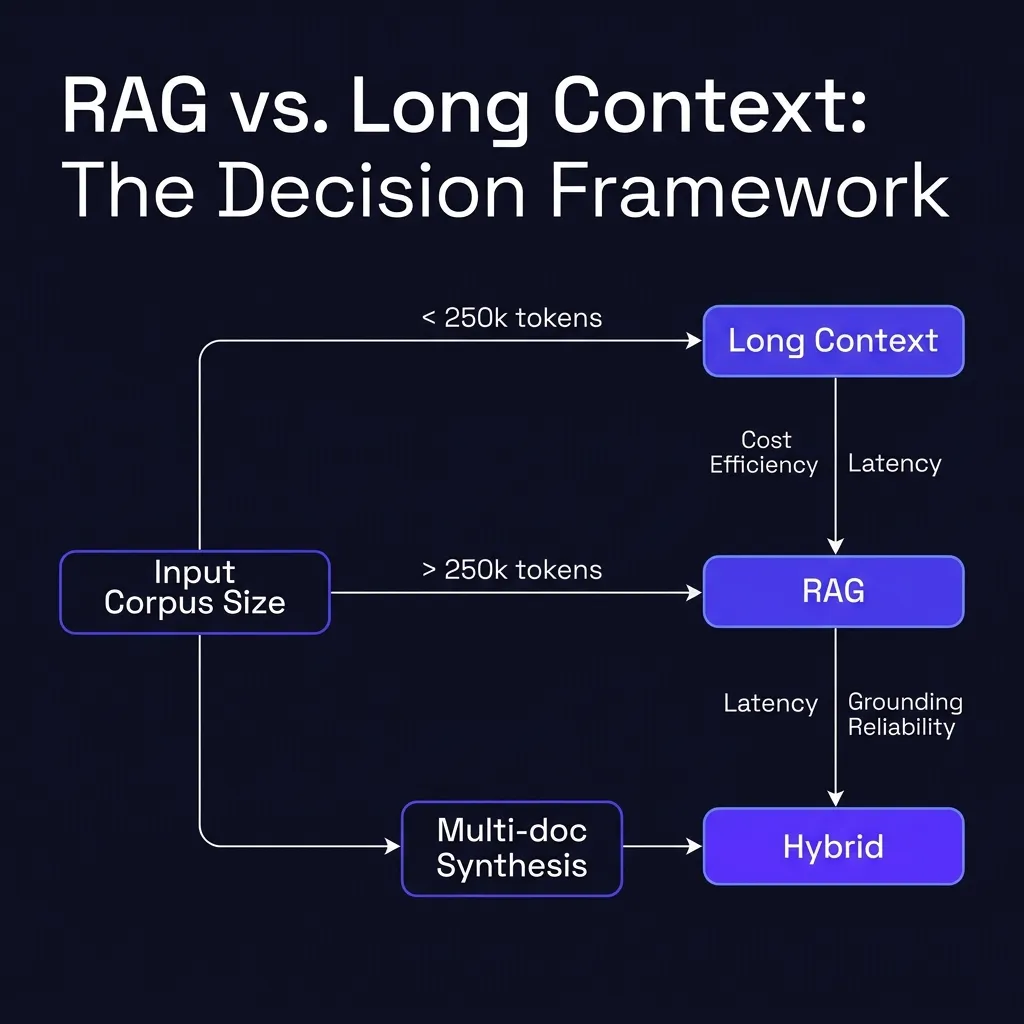
Use this as your default:
- If the answer should come from a small, stable set of documents: start with long context.
- If the answer should come from a large or frequently changing corpus: use RAG.
- If the answer is hard, multi-step, or needs multiple documents: use hybrid.
Everything else is detail. The rest of this post is the detail you’ll actually need in production.
Quick comparison (what you’re really buying)
| Approach | What you buy | What you pay | Where it breaks |
|---|---|---|---|
| Long context | Simplicity, fast iteration | Token cost, “prompt as storage” drift | “Lost in the middle”, repeated re-sends, weak provenance |
| RAG | Scalability, grounding, updatability | Pipeline complexity, retrieval failures | Bad chunking, wrong hits, missing context cohesion |
| Hybrid | Best of both (usually) | More moving parts | Over-engineering, brittle packing rules |
Long context: when it’s the right tool
Long context is best when you can treat the prompt like a temporary working set:
- a single repo snapshot you’re reasoning about
- a small set of policy docs
- a few PDFs you can upload once and keep stable
- a “case file” for one user, one project, one ticket
The real advantage: fewer failure modes per request
With long context, you don’t have to debug:
- embedding choices
- chunk sizes
- re-ranking
- filters
- stale indexes
- retrieval misses
If your corpus is small enough, “everything is in the prompt” is a reliability win.
The real cost: you end up paying for the same text repeatedly
Even with prompt caching, long-context apps can accidentally turn into a token furnace if you keep re-sending large stable documents. OpenAI’s guidance on prompt caching exists for a reason: if you’re building a product, you need a caching strategy (or you will spend money on text that never changes). (See: OpenAI API docs on prompt caching.)
Cost reality: long context is not priced linearly
This is not just “tokens are expensive.” Some long-context models explicitly price very large prompts differently.
As of March 2026, OpenAI’s GPT‑5.4 docs note that prompts above a large input threshold (272K input tokens) can trigger a higher multiplier for the rest of the session. If your app keeps dumping everything into context, you can accidentally push yourself into the expensive mode permanently.
Practical fix: keep your “always-on” prompt small, and treat large context ingestion as a special mode — or offload the bulk of the corpus to retrieval.
“Lost in the middle” is not a meme
Long context is not an infinite memory. Models can still underweight or miss relevant details when they’re buried inside huge prompts. If you want an evidence-backed explanation of that failure mode, read Lost in the Middle: How Language Models Use Long Contexts.
Practical fix: treat long context as a store for the working set, not for the entire world.
RAG: when retrieval is non-negotiable
RAG is the right tool when any of these are true:
- Your corpus is large (hundreds/thousands of docs).
- Your corpus changes often (wikis, tickets, releases, policies).
- You need freshness (you can’t ship stale answers).
- You need provenance (quotes, links, “show me where this came from”).
- You need access control per user/tenant/document.
Under the hood, you’re building what the original RAG paper described: a language model that conditions on retrieved documents instead of pretending it can store everything in parameters. The details have changed since 2020, but the point hasn’t.
RAG’s core failure mode is retrieval, not generation
When RAG fails, it usually fails because:
- you retrieved the wrong chunk
- you retrieved the right chunk but cut out the crucial paragraph
- you retrieved multiple chunks that contradict each other
- you didn’t retrieve the one doc that mattered (coverage gap)
If you want RAG to be reliable, you don’t “prompt better.” You make retrieval measurable.
Minimum viable RAG evals:
- Hit rate: did we retrieve the doc that contains the answer?
- Faithfulness: does the output stay consistent with retrieved text?
- Citation quality: do links/quotes point to the right passage?
The hybrid approach (what most serious systems end up doing)
The best pattern for most builder workloads in 2026 is:
- Retrieve a small set of relevant documents (RAG)
- Pack them into a deliberate order (most relevant first)
- Use the long context window to reason across them
That hybrid unlocks something that pure RAG often struggles with: cross-document synthesis without losing grounding.
A simple packing rule that works
Pack retrieved context like this:
- a short “query intent” summary (what the user is trying to do)
- the top 3–8 retrieved chunks (in rank order)
- a “known constraints” footer (policies, style rules, safety rails)
Then keep the rest of the session small by writing a compact running summary (what changed, what was decided, what remains).
If you’re building coding agents, this is the same idea as “diffs and constraints as the working set” rather than “stuff the repo every time.”
Here’s a minimal hybrid prompt layout you can steal:
SYSTEM: You are a careful assistant. Use only provided sources when answering.
USER: Question: <the user’s question>
USER: Intent: <one sentence summary>
CONTEXT (ranked):
1) <top chunk>
2) <second chunk>
3) <third chunk>
CONSTRAINTS:
- <policy or style rules>
- <what to do when unsure>A practical build path (don’t over-engineer on day one)
Here is a build sequence that avoids the two classic mistakes (premature RAG, and prompt-bloating forever):
Step 1: Start with long context + working-set discipline
- keep stable docs out of the prompt unless needed
- summarize older turns into a compact memory
- store “facts” in a structured format you can re-hydrate (JSON notes, bullet decisions)
If your answers are good and your costs are sane, you’re done.
Step 2: Add retrieval only when you feel real pain
The “real pain” signals:
- you can’t fit the relevant docs without constantly trimming
- you can’t keep answers fresh without re-uploading and re-sending
- you need citations and provenance for trust
- your corpus is too big to treat as a working set
At that point, build a small RAG layer. If you’re on OpenAI’s stack, the File Search tool and the official RAG guide are a pragmatic starting point because they standardize the “upload → index → retrieve” loop.
Step 3: Go hybrid when multi-doc reasoning becomes the bottleneck
Hybrid is where you get the “actually useful” behavior:
- the model stays grounded because retrieval keeps it honest
- the model stays coherent because long context lets it synthesize
Don’t forget the non-technical reasons (security and compliance)
Your choice is not just about quality.
- Data minimization: long context can encourage “send everything,” which is risky.
- Access control: RAG systems can filter at retrieval time; prompts can’t.
- Auditability: RAG can store what was retrieved; giant prompts often become untraceable blobs.
If you care about reducing hallucinations and increasing verifiable answers, RAG-style grounding is still one of the cleanest tools we have. (Related: Why AI Hallucinates.)
Practical recommendations (what I’d ship in 2026)
- Start with long context for small corpora and fast iteration.
- Add prompt caching early if you have any stable, repeated context.
- Add RAG the moment “freshness + scale + provenance” become requirements.
- Move to a hybrid pattern for anything that needs cross-doc synthesis.
- Add evals that measure retrieval quality, not just output vibe.
Long context is not a replacement for RAG. It’s a bigger whiteboard.
RAG is not a replacement for long context. It’s the filing cabinet.
Good systems use both.